
Google has found a better, more efficient translation method.
It doesn't rely on text to provide output; instead it just converts speech to speech.
Google Translate helps you talk to people who don’t speak the same language as you using its inbuilt conversation mode. You can input a message in speech format in say, English, and have it translated to speech in say, Japanese. But to do that, it first breaks down your speech into words in text format, performs a text-to-text translation, and then plays back the translated text using good old TTS (text-to-speech synthesis). Google is proposing a new method now: the Translatotron direct speech-to-speech translation model.
Still in an experimental phase, the Translatotron model drops the middle man. In other words, it directly translates input taken as speech and plays it back using a single attentive sequence-to-sequence model. According to Google, this direct translation model has many advantages, including “faster inference speed, naturally avoiding compounding errors between recognition and translation, making it straightforward to retain the voice of the original speaker after translation, and better handling of words that do not need to be translated.”
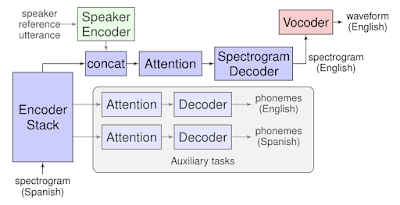
Google's diagram on how Translatotron works
Work on such a direct translation model began in 2016, writes Google in its blog post on the matter. A year later, the developer behind the world-famous Android OS demonstrated that the new direct translation was faster and more efficient. According to Google, Translatotron takes source spectrograms as input and generates equivalent spectrograms for the necessary language. “During training, the sequence-to-sequence model uses a multitask objective to predict source and target transcripts at the same time as generating target spectrograms. However, no transcripts or other intermediate text representations are used during inference,” writes Google.
Though Google is now in possession of a new translation model, it still isn’t ready to incorporate it into Google Translate and other related tools. The new system is falling behind on BLEU score, meaning the translations aren’t accurate enough yet. On the plus side, the new model retains the user’s natural voice even after translation as it doesn’t use TTS for output. “By incorporating a speaker encoder network, Translatotron is also able to retain the original speaker’s vocal characteristics in the translated speech, which makes the translated speech sound more natural and less jarring,” adds Google.
Vignesh Giridharan
Progressively identifies more with the term ‘legacy device’ as time marches on. View Full Profile



