Google DeepMind is developing video-to-audio (V2A) technology.
This tech combines video pixels with natural language text prompts to generate “rich soundscapes for the on-screen action."
V2A can generate an unlimited number of soundtracks for any video input.

Video generation models are advancing rapidly, yet many current systems produce only silent videos. A significant upcoming advancement is creating soundtracks for these silent films. Google DeepMind is developing video-to-audio (V2A) technology, enabling synchronised audiovisual generation and bringing generated movies to life.
Let’s take a look at the details.
Also read: Google Deepmind’s new AI agent ‘SIMA’ will be your in-game teammate: Check details
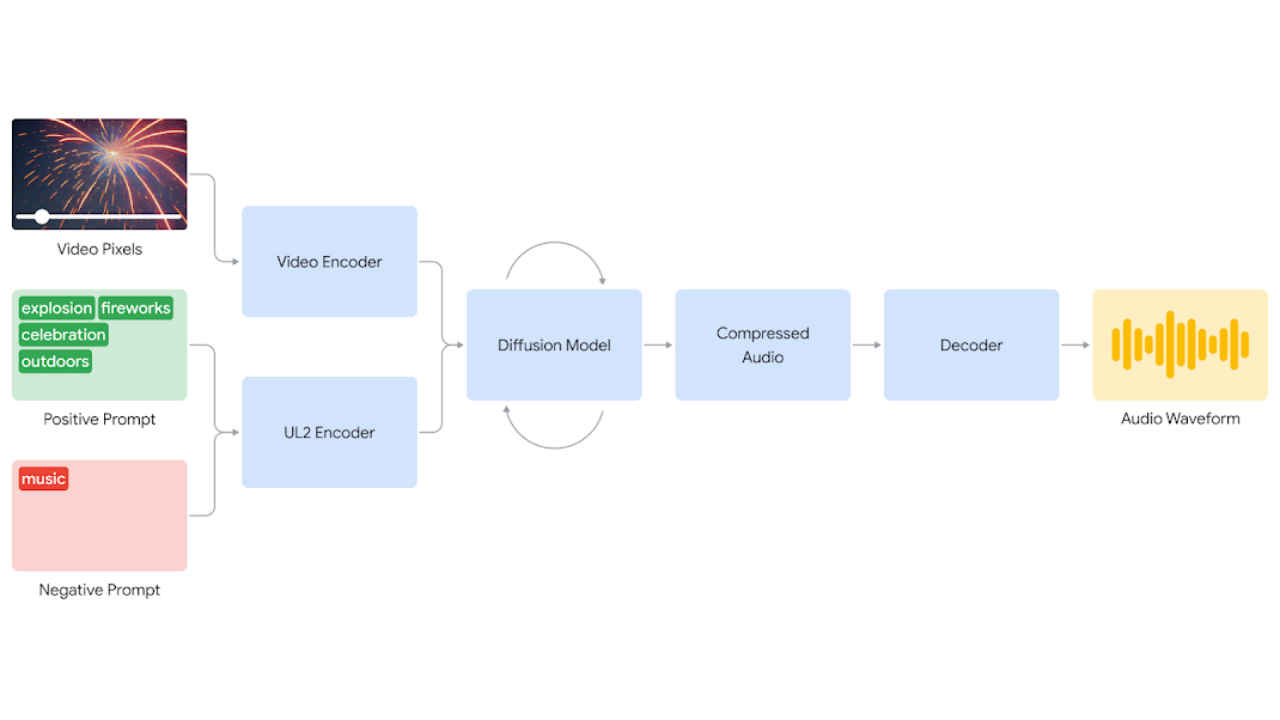
The V2A technology combines video pixels with natural language text prompts to generate “rich soundscapes for the on-screen action,” the company said.
This technology is pairable with video generation models like Veo to create shots with a dramatic score, realistic sound effects or dialogue that matches the characters and tone of a video.
It can also generate soundtracks for a range of traditional footage, including archival material, silent films and more — opening a wider range of creative opportunities.
It’s worth noting that V2A can generate an unlimited number of soundtracks for any video input.
Also read: Google Deepmind’s new AlphaFold 3 AI can model proteins, DNA & RNA: Details here
How it works?
“We experimented with autoregressive and diffusion approaches to discover the most scalable AI architecture, and the diffusion-based approach for audio generation gave the most realistic and compelling results for synchronising video and audio information,” the company said.
The V2A system begins by encoding video input into a compressed representation. The diffusion model then iteratively refines the audio from random noise, guided by the visual input and natural language prompts. This process generates synchronised, realistic audio that is closely aligned with the prompt. Finally, the audio output is decoded, transformed into an audio waveform, and combined with the video data.
To generate higher quality audio and add the ability to guide the model towards generating specific sounds, the company has added information to the training process like AI-generated annotations with detailed descriptions of sound and transcripts of spoken dialogue.
Ayushi Jain
Ayushi works as Chief Copy Editor at Digit, covering everything from breaking tech news to in-depth smartphone reviews. Prior to Digit, she was part of the editorial team at IANS. View Full Profile