When AMD announced its Ryzen AI 300 series processors at Computex 2024, the focus was on AI performance and the XDNA 2 NPU. We’ve already covered the AMD XDNA 2 NPU architecture and how it achieves 50 TOPS of performance, which is the highest number so far as pure claimed NPU performance is concerned (Intel NPU 4 on Lunar Lake claims 48 TOPS). In this article, we will take a closer look at the Zen 5 processor architecture and the gains it brings over Zen 4.
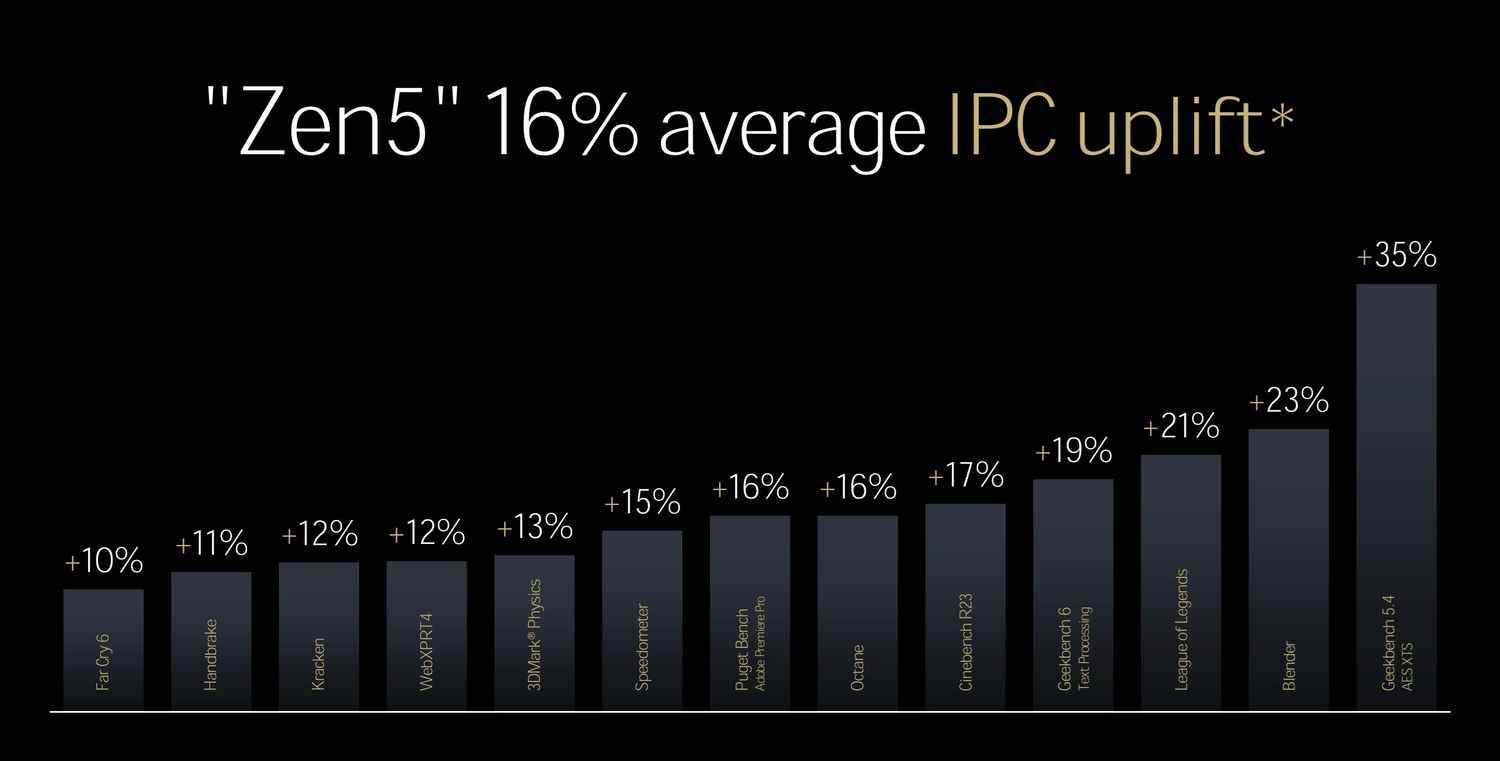
AMD’s Zen 5 core, powering the upcoming Ryzen 9000-series CPUs and Ryzen AI 300-series processors, boasts a 16% average increase in instructions per clock (IPC) on the back of architectural enhancements and a node shrink to TSMC’s 4nm process technology. The Zen 5 architecture boasts significant improvements in performance and efficiency, thanks to a redesigned front end, wider execution pipelines, and enhanced cache hierarchy.
The new front-end changes include a revamped fetch, decode, and dispatch mechanism that yields more instructions to the back end. Additionally, branch prediction accuracy has been improved, with more predictions per cycle. The dispatch and execution engine has been enhanced to support up to 8 instructions per cycle, with a unified scheduler and expanded execution window.
The cache hierarchy has also been improved, with a 50% increase in data cache size to 48 kilobytes, without increasing latency. Furthermore, the data bandwidth has been doubled, with support for 512-bit loads and stores. The AVX math unit has been doubled to a physical 512-bit wide pipeline, resulting in reduced latency and increased throughput.
According to AMD, the Zen 5 architecture boasts several enhancements that collectively reduce latency and boost performance. Improved branch prediction accuracy and increased predictions per cycle minimize latency while dual-porting and decreased latency in caches enable more efficient access. Wider execution pipelines allow for simultaneous execution of more instructions, reducing latency.
Additionally, doubled data bandwidth enables faster transfer of data between caches, and an optimized scheduling algorithm minimizes stalls and improves resource utilization. Finally, tuned data prefetch algorithms recognize stride patterns, prefetching data more efficiently and reducing latency. These advancements combined deliver significant performance gains and reduced latency, making Zen 5 a formidable processor architecture.
“Zen 5 will not disappoint you with the kind of performance improvements that we’ve brought, and we won’t let up going forward,” said Mark Papermaster, EVP and CTO at AMD. “It’s going to be a pedestal that we’re going to build upon the next several generations of Zen,” he said. Mark Papermaster further emphasised, “We’re very happy with the improvements that we made. We could not be more proud with our new math acceleration unit.” Mark Papermaster reiterated their commitment to innovation, stating, “We will not slow down on our innovations at AMD.”
We’ll continue to deliver leadership and bring delightful experiences to our customers.” He added, “We think broadly with our IP designs in terms of how we deploy it, in terms of how we optimize it to be both high performant and highly efficient, and nothing has changed at all in that philosophy and that approach with Zen 5.” Zen 5 is poised to “absolutely excel at AI data preparation and general-purpose CPU workloads.” Mark Papermaster affirmed, “We’re maniacally focused on execution and delivering new capabilities on a regular cadence”, Mark affirms.
As AMD’s Zen 5 architecture gears up to take on Intel’s Lunar Lake and Qualcomm’s ARM-based Snapdragon X-Elite chips, the burning question is: how will these impressive specs translate to real-world performance? The answer lies in the harmonious balance between the Zen 5 core, XDNA 2 NPU, and revamped RDNA 3.5 iGPU. And as we’ve seen with the past few generations, increasingly the GPU is doing all the heavy lifting when it comes to AI workloads. And the focus and reliance on GPU performance is only going to get heavier as we move further into the generative AI era.
Benchmark leaks suggest that RDNA 3.5 iGPU is a major step up in integrated graphics performance, possibly rivaling some entry-level discrete GPUs. We’re eager to review the ASUS ZenBook S16, which we previewed at AMD Tech Day 2024. Our next article will dive deeper into RDNA 3.5’s enhancements.
Also read: AMD launches 8700F and 8400F Zen 4 CPUs without RDNA 3 integrated graphics
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}