A patent application revealed earlier this year hints at a future where major tech companies use a treasure trove of healthcare data to predict healthcare events

Back in May 2018, Owkin, a medical research machine learning startup, received $5 million in Series A follow-on funds from GV, Alphabet’s venture investment arm. For the uninitiated, Alphabet is the parent company of Google that was created when the organisation went through a massive restructuring back in 2015. Cut to 2019, in February, the US Patent and Trademark Office published a Google patent about a predictive EHR system. The patent was apparently filed back in 2017 and hasn’t been granted yet.
EHR
Before we explain why this is important, it is essential to know what EHR is. Electronic health records, or EHRs, are an organised collection of patient data that can be shared across different healthcare situations. In terms of the data stored, EHR may include a wide variety of markers like demographics, medical history, medication and allergies, immunization status, laboratory test results, radiology images, vital signs, personal statistics like age and weight, and billing information. Such a system allows doctors to access all of this information about a patient, new or old, as it is usually linked to identifiers such as social security numbers in the US. However, if technology based on the Google patent application came to be, their usefulness could go beyond that.
The patent
The Google patent in question intends to use EHR in multiple ways by subjecting it to machine learning. The massive amount of data in there definitely holds a lot of potential for many use cases. For instance, the first part will focus on aggregating such information from multiple sources and organisations. On the face of it, this is a huge task in itself because of how healthcare data can vary from organisation to organisation. As Google put it in a blog post dated back to May 2018, even something as basic as the temperature can have different meanings depending on where it was measured from – under the tongue, through your eardrum, or on your forehead. However, Google has defined its approach to this problem by applying a new model to track health records, built on top of the open Fast Healthcare Interoperability Resources (FHIR) standard described earlier by them.
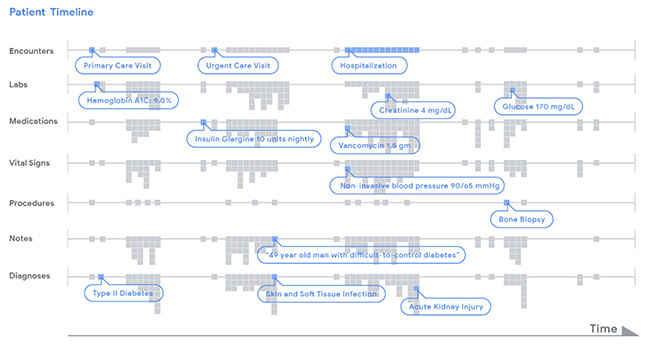
Data in a patient's record is represented as a timeline. For illustrative purposes, different types of clinical data (e.g. encounters, lab tests) are displayed by row. Each piece of data, indicated as a little grey dot, is stored in FHIR, an open data standard that can be used by any healthcare institution. A deep learning model analyzed a patient's chart by reading the timeline from left to right, from the beginning of a chart to the current hospitalization, and used this data to make different types of predictions. (Source: Google)
The second part of this system would be the application of deep learning to the standardised data. A chronological reading of all the data points involved helps to highlight the factors that are most crucial for prediction purposes. This data would then be visible in the third part, a doctor facing interface that features these predictions in a format consumable to them. Another aspect of this would be to highlight pertinent medical events and data from the past, which removes the need for the physician to go through a large number of notes and records related to the patient.
While Google isn’t providing any new comments on the system, the blog post mentioned earlier goes on to show how the investigation used 46,864,534,945 retrospective EHR data points collected from 216,221 adult patients hospitalized for at least 24 hours at two US academic medical centres. Armed with this data, the deep learning models were able to successfully predict in-hospital mortality, unplanned re-admissions in a 30-day span, elongated stay durations and ultimately, diagnoses at the time of discharge with an accuracy that was not only superior to a manual analysis of the data, but also predictive systems that worked off of smaller data sets.
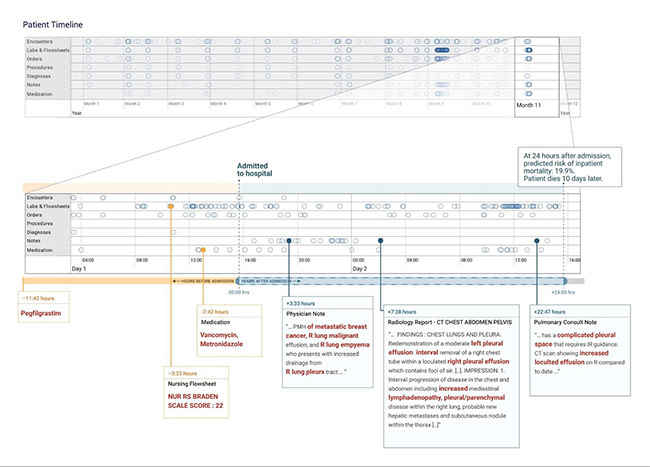
A deep learning model was used to render a prediction 24 hours after a patient was admitted to the hospital. The timeline (top of figure) contains months of historical data and the most recent data is shown enlarged in the middle. The model "attended" to information highlighted in red that was in the patient's chart to "explain" its prediction. In this case study, the model highlighted pieces of information that make sense clinically. (Source: Google Research)
The potential and the competition
Before EHR, there was a lack of enough data to efficiently take actions in healthcare for the patient’s benefit. Since EHR, it can be argued that there’s an overabundance of data that can prove to be a hindrance to physicians and medical professionals. A system like the one described in the patent answers two important questions that plague physicians every day – which patient requires my attention the most, and which part of their records should I focus on.
Last year’s report by MeitY titled Adoption of Electronic Health Records: A Roadmap for India, highlights the obstacles to a centralised system like this in India. A large number of hospitals and medical facilities in our country lack the basic information and communication infrastructure that is crucial for such systems to be reliable and operational. On top of that, much of the EHR data in India is stored in privatised silos, with no exchange between private hospitals, which see 75% of outpatients and 60% of inpatients in India.
While the exact situation of the doctor-patient ratio seems to be dependent on whether you take only allopathic doctors into consideration or not, it is no secret that the healthcare system in the country could improve, especially when it comes to better patient care and efficiency. A system like this, from a company, as deeply invested in India as Google, could prove to be a significant change-maker. Unless competing offerings from Apple and Amazon break ground first.
Amazon is also invested in this area with Amazon Comprehend Medical, last explained by the company in November 2018, working almost identically to Google’s project. Interestingly, Amazon has also filed a patent earlier for Alexa to be able to pick up on a cold or a cough from a person’s voice, detecting a deviation from the norm and maybe even suggesting possible remedies or medication.
Apple’s ResearchKit puts the iPhone’s sensors at the disposal of researchers to carry out studies.
Apple, on the other hand, has also announced its intentions to move into the same space. With Apple Watch with a single-lead ECG, as well as the Apple Health Record, there are other things also that indicate Apple’s intentions to be a platform friendly to developers looking to build healthcare offerings off of their platform. ResearchKit and CareKit SDKs allow researchers to use the iPhone for research purposes and also to use its sensors to monitor patients. Multiple startups have used these SDKs to build their offerings, like Glow and One Drop. If Google makes something similar available to startups, especially in India, it could open up the doors to a lot of Indian startups to leverage Google’s massive data mine to build affordable healthcare software for the masses.