
Whether it’s ChatGPT since the past couple of years or DeepSeek more recently, the field of artificial intelligence (AI) has seen rapid advancements, with models becoming increasingly large and complex. These sophisticated models, often called “teacher models,” can achieve remarkable accuracy but require significant computational resources to operate. This makes them impractical for many real-world applications where efficiency is crucial.
Also read: DeepSeek AI: How this free LLM is shaking up AI industry
Model distillation, or knowledge distillation, addresses this challenge by transferring the knowledge of a large model into a smaller, more efficient one. The smaller model, known as the “student model,” is trained to replicate the performance of the teacher model while being faster and less resource-intensive.
How AI model distillation works
The process of model distillation begins with a pre-trained teacher model. This teacher model has already been trained on a large dataset and is capable of making highly accurate predictions. However, instead of using the teacher model directly for tasks, a smaller student model is trained to mimic its behaviour.
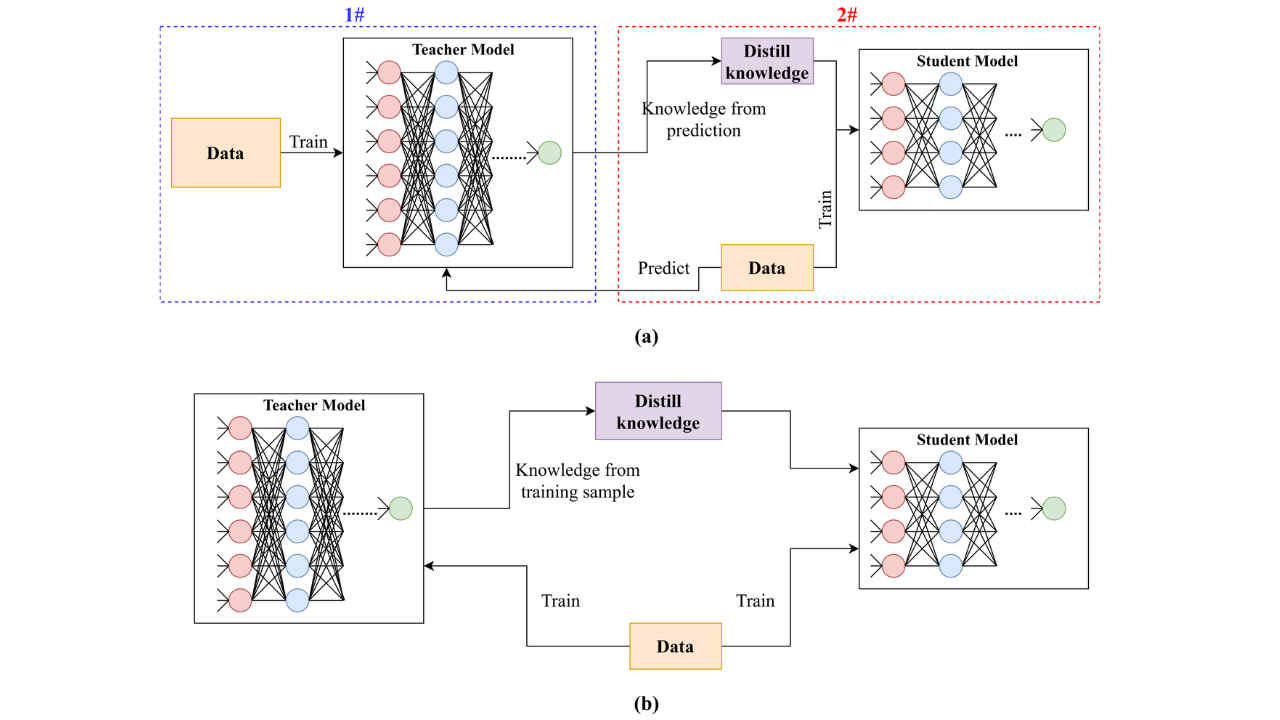
During training, the student model learns from two sources: the original data and the outputs generated by the teacher model. These outputs are often referred to as “soft targets” or “logits.” Unlike hard labels, which only indicate the correct class (e.g., “cat” or “dog”), soft targets provide richer information by showing the probabilities assigned to all possible classes. For example, if an image contains a cat, the teacher might assign a high probability to “cat,” but also some probability to “dog” or “fox,” reflecting subtle similarities between these categories.
Also read: DeepSeek vs OpenAI: Why ChatGPT maker says DeepSeek stole its tech to build rival AI
This additional information helps the student model understand not just what the correct answer is but also why it is correct. It captures relationships between different classes and provides insights into how the teacher processes data. As a result, the student can learn more effectively than if it were trained on hard labels alone.
In some cases, distillation goes beyond just output probabilities. Advanced techniques involve transferring knowledge from the internal layers of the teacher model. This means that instead of only learning from final predictions, the student also mimics intermediate representations or features generated by the teacher during its computations. This approach allows the student to replicate not just what the teacher predicts but also how it arrives at those predictions.
Another important aspect of distillation is temperature scaling. During training, a parameter called “temperature” is applied to soften or smooth out the probabilities produced by the teacher. Higher temperatures make the probabilities less sharp and easier for the student to interpret, facilitating better learning. Once training is complete, this temperature adjustment is no longer needed for inference.

Finally, some methods focus on capturing relationships between data points rather than individual predictions. For instance, relation-based distillation trains the student to understand how different inputs relate to one another according to the teacher’s perspective. This can be particularly useful in tasks where context or relative positioning matters.
Also read: DeepSeek is call to action for Indian AI innovation, says Gartner
By combining these techniques, model distillation enables a smaller student model to achieve performance levels close to that of its larger counterpart while being significantly more efficient in terms of computation and memory usage.
Benefits of distillation of AI models
Model distillation offers several advantages. It allows for smaller models that retain much of the accuracy of their larger counterparts while being computationally efficient. These compact models are ideal for deployment on devices with limited resources, such as smartphones or edge devices.
Also read: Stargate to OpenAI: Why Elon Musk and Sam Altman are still fighting
Additionally, distilled models reduce operational costs by lowering energy consumption during inference and training. They also enable faster processing times, making them suitable for real-time applications like fraud detection or personalised recommendations.
Applications in AI
Model distillation has become a key tool in fields like natural language processing (NLP) and computer vision. For instance, it is used in tasks such as text generation, machine translation, image recognition, and object detection.

A notable example is Stanford’s Alpaca model, which was distilled from Meta’s LLaMA 7B model to achieve high performance with reduced computational demands.
Challenges and future potential
While model distillation offers significant benefits, it comes with challenges. Selecting appropriate architectures for both teacher and student models is critical for effective knowledge transfer without degrading performance.
Also read: KOGO OS aims to popularise LLM-agnostic approach to AI: Here’s how
Additionally, substantial computational resources may still be required during initial training. Despite these challenges, combining distillation with other optimisation techniques like quantisation or pruning holds promise for further improving efficiency and scalability.
In summary, model distillation bridges the gap between large AI models and practical deployment constraints. By enabling smaller models to inherit capabilities from larger ones while being faster and more efficient, it plays a vital role in advancing AI technologies for real-world applications.
Sagar Sharma
A software engineer who happens to love testing computers and sometimes they crash. While reviving his crashed system, you can find him reading literature, manga, or watering plants. View Full Profile