
The mind maps that digital brains have for language translations can look very pretty.
Major tech companies and academic institutions around the world are competing to develop artificial intelligence that is the most accurate at translating one language to another. Because of the way machine learning works, the approaches and the results are often unexpected. In its essence, all the systems developed are similar. A neural network is “trained” to translate from one language to another, by providing it with pairs of translations – that is an original work, and the same work translated by a human. The neural network, which is a digital simulation of the structures in the brain, then learns to associate words and sentence constructions between the two languages. The more material that a neural network is fed, the more accurate the translation is. When the neural network is then given with a sentence in one language, the output is the translation in another language.
Zero Shot Translation
Google Translate is perhaps the most used machine translation tool, thanks to how closely it is integrated with the search engine and the Android OS. Over 130 languages are supported by Google translate. In 2016, Google moved to a new system called Google Neural Machine Translation (GNMT). Now, the system initially had “pairs” of language in which it is trained. If the system is trained to translate between English and Japanese, that is one pair. Korean and English is another pair. Now, the system is not explicitly trained to translate between Korean and Japanese. This is a capability that Google engineers needed if they wanted to quickly support all the 130 languages in GNMT, without having to laboriously train every possible language pair combination. In a first of its kind demonstration of “transfer learning”, the engineers managed to translate directly from Japanese to Korean, even though the machine had not been trained for that task. This is referred to as “zero shot translation”.
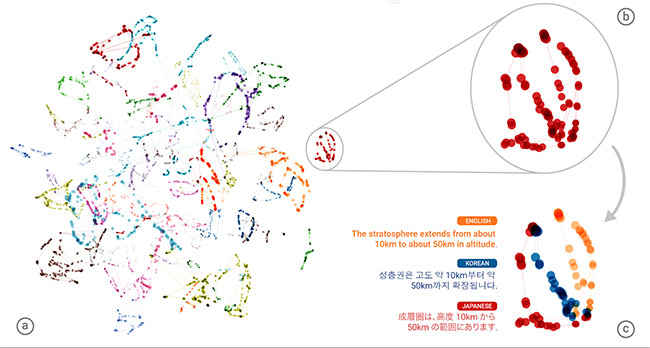
The Google engineers peeked into the brain of the machine, to understand how exactly the translation was occurring. A three-dimensional map of the internal network data was used for this purpose. In the overall map, the sentences with the same meanings in all the three languages are grouped by the same colour. The cluster of red dots is visualised in three colours, according to the language. The cluster shows that the neural network is encoding the meaning of the sentences, rather than simply translating the sentence word for word. The cluster of red dots is evidence that the neural network has developed an “interlingua”, an internal language that only the machine can understand, which it uses to translate between other languages.
Universal Lexical Representation
One of the problems with training the models for machine translation is the amount of resources available for the training. For any given language pair, it is easy to find a lot of material for the way the language is written. Legal or political documents and news reports that are translated by humans are some resources that are easily available in both languages. When it comes to the way language is spoken, or for informal text conversations, such “parallel” resources are more difficult to come by. As mentioned before, the more material a neural network has to learn from, the more accurate it gets at its task. There are over 7,000 languages in the world, and most of them simply do not have enough resources to train a neural network for machine translation. These low resource languages may have very few parallel sentences when paired with another language, but have plenty of monolingual data. Microsoft researchers came up with an innovative way to use the available data and make accurate language translation models.
Microsoft tackled this problem by using what is called a “universal lexical representation”. This approach involves taking a bunch of languages and projecting the meanings of the words onto a shared space. Dictionaries or the small amount of parallel data available is used for the operation. In this example, parallel data from Spanish (ES), French (FR), Italian (IT) and Portuguese (PT) were used to project on a shared English representation, in an effort to translate Romanian (RO), which had sparse amounts of parallel data.
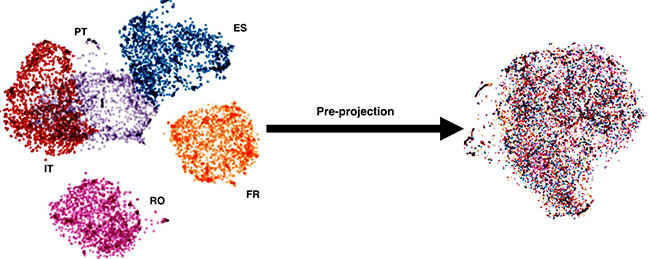
Now, the system can “guess” the meanings of entirely novel words, which it has not been trained to recognise. It does this by finding similar representations from the shared space and weighing the options. For example, “toamna”, the Romanian word for “autumn”, is weighted closer to “autumn”, than say, “spring”. The system is smart enough to switch between different modes according to the demands of the situation when identifying novel words. This may involve picking languages from the same language group, or picking up from languages that have geographic overlap. The approach is particularly useful for translating Indic languages, which are considered low resource languages.
Word Embeddings
Finding material to train a pair of languages for about the 100 languages supported by most translation services is difficult enough, but imagine if the approach was the only one available for all the 7,000 spoken languages in the world. To overcome this obstacle, researchers from MIT developed a method that does not depend on training from a language pair at all. This monolingual training technique to feed the vocabulary of a language into a computational space. Essentially, this is an array of numbers that represent the meanings of the words from each language. The words with similar meanings are clustered together. For example, the word “mother”, may appear close to the word “father”, and all the twelve months will form a close cluster of words. Now the absolute positions of the words embedded within the computational space may be different from one language to another, but what does not change is the distance between the words. In all the languages, the words with similar meanings will be located at a similar distance to each other. Then, it is a matter of applying statistical techniques to the array of words, to find any cluster of words with a similar meaning from another language. This allows translation from one language to another, even though the machine learning system has not been trained with a language pair.
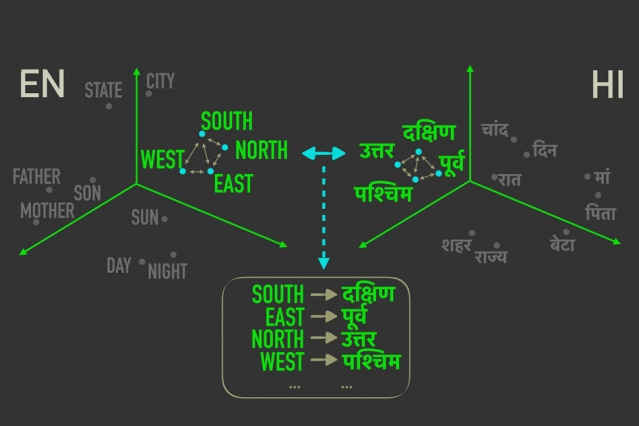
In the example above, the four directions in Hindi are aligned with the four directions in English, although they are located in different spaces. If you look at the other words represented in the computational space, although they may not be located in the same place in both the models, the relative distance between them is roughly the same – though not exactly the same. The system goes around this obstacle by weighing, or giving a probability for the words that are most likely to correspond between the two spaces. The words with the highest probabilities are picked for the translation. Finding the corresponding word vectors in a matrix is a far faster process than the other, more traditional approaches, and the whole thing can take place in an unsupervised manner. That means, that there is no need for human intervention to fine tune the corresponding meanings. The computational space of the word representations of two languages can be aligned entirely by just measuring the distance between the representations. The approach used by the MIT researchers has one other advantage, which could be of use to those who study languages. It gives a simple score for how similar to computational spaces for the languages are. French and Italian, which share a common history and origin, get a score of 1. Chinese, scores anywhere between 6 and 9 when compared to other languages. The more similar the languages are, the lower the score is.
Unsupervised Machine Translation
Researchers from Facebook used a similar approach as MIT to develop a machine translation system of their own. The system was trained in single languages using dictionaries, and the words were mapped to a two-dimensional space. Now the relative distances between the words are preserved, and the two-dimensional space only has to be rotated to correctly map the entire language space to another language. Facebook researchers used the simple method of checking the words that appeared around a particular word to build these spaces. This exploits the physicality of the world we live in, which is then described in a language. For example, the word “furry” is more likely to appear next to the word “kitten”, as against the word “rocket”. To translate between the languages, all the machine needs to do is find the closest word in the corresponding target language. The approach also allows for rapid translation without the need for training based on language pairs.
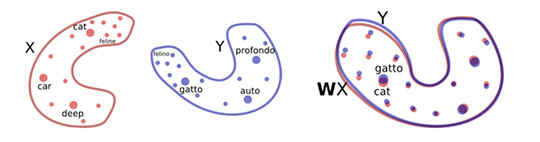
Word by word translation is incorrigible, and just not good enough for translating one language to another. The approach used by the Facebook developers is to use language modelling, to find out what makes fluent sentences within a single language. The models that identify fluent sentences in a single language, is trained on monolingual data, and does not need a corresponding translation from another language. The approach works for language pairs that are very different from each other (such as English and Russian), language pairs that have very few common resources (such as English and Romanian), as well as language pairs that are both low in resources and very different from each other (such as English and Urdu).
The techniques discussed here can potentially be used to solve other problems, apart from translating between two languages.
Aditya Madanapalle
Aditya Madanapalle, has studied journalism, multimedia technologies and ancient runes, used to make the covermount DVDs when they were still a thing, but now focuses on the science stories and features. View Full Profile



