
The race to perfect generative AI models and develop ones that can mimic the human brain is on! Research conglomerates across the board are rushing to release their AI models, which aim to perfect the process of complex problem-solving by becoming increasingly more intuitive to use. OpenAI has been a leader in this space and has made very capable models like GPT-4o available to the public. The latest addition to their arsenal is OpenAI o1, also known as OpenAI Strawberry. As this new AI model makes way into the hands of the regular folk, let’s take a look at the five key ways in which Open AI’s Strawberry claims to be better than ChatGPT 4o –
OpenAI’s Model o1 is more resilient to generating harmful content
Ever since the inception of generative AI, bad actors have been trying to bypass the guardrails set in place to prevent the generation of harmful content. The most common way of doing this is – jailbreaking. Taking note of the incessant problem of jailbreaking AI, OpenAI, with their o1 model, has added enhanced protection against jailbreaking and other ways in which bad actors might try and generate harmful content using the model.
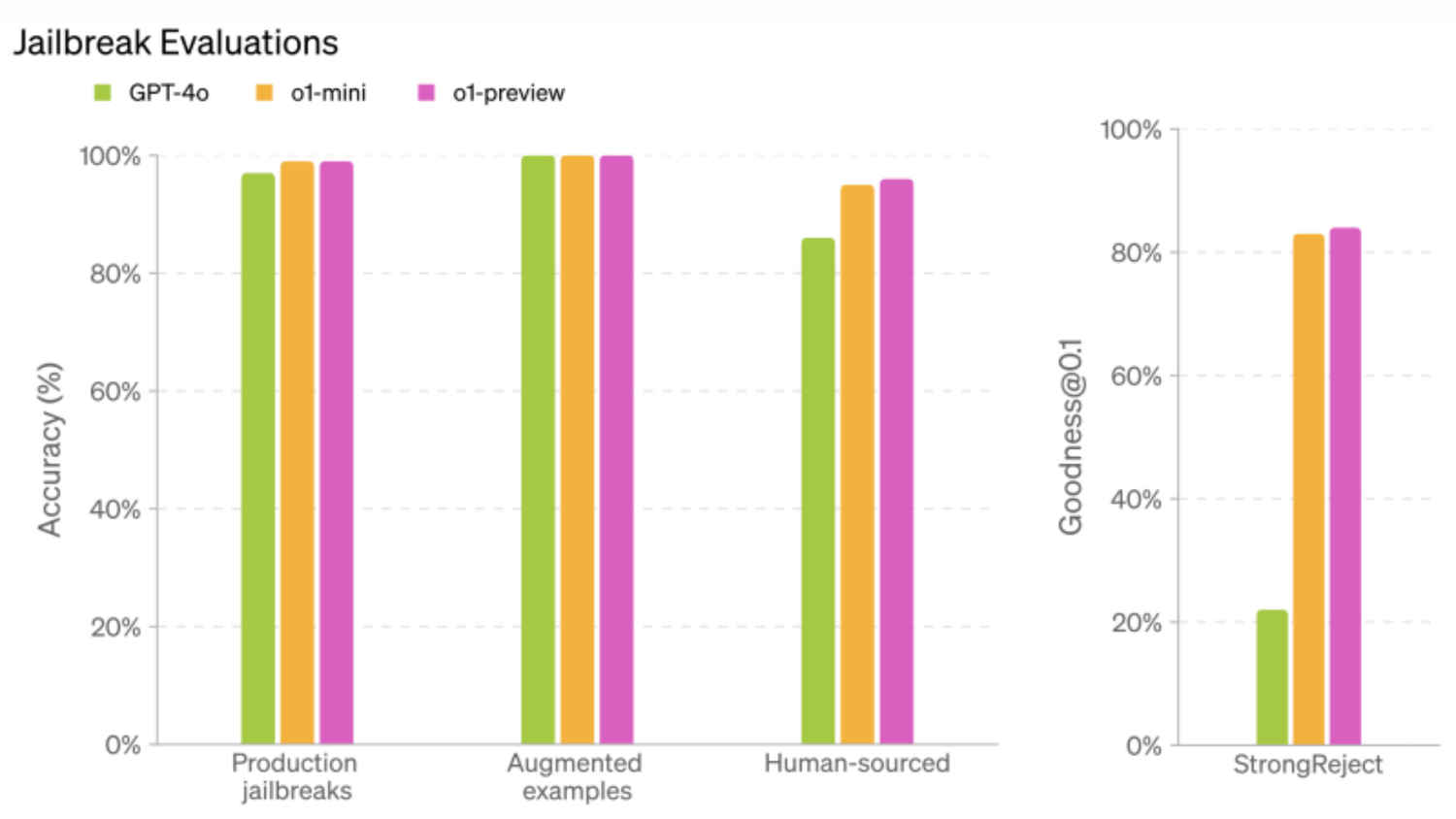
By deploying the learnings from their internal “preparedness framework” and red-teaming amongst a host of processes, OpenAI was able to ensure that the model stays better protected against generating harmful content. In their documentation about o1, they noted that the model scored 84 points on a scale of 0-100, which is significantly higher than that of GPT-4o, which managed a score of just 22 points.
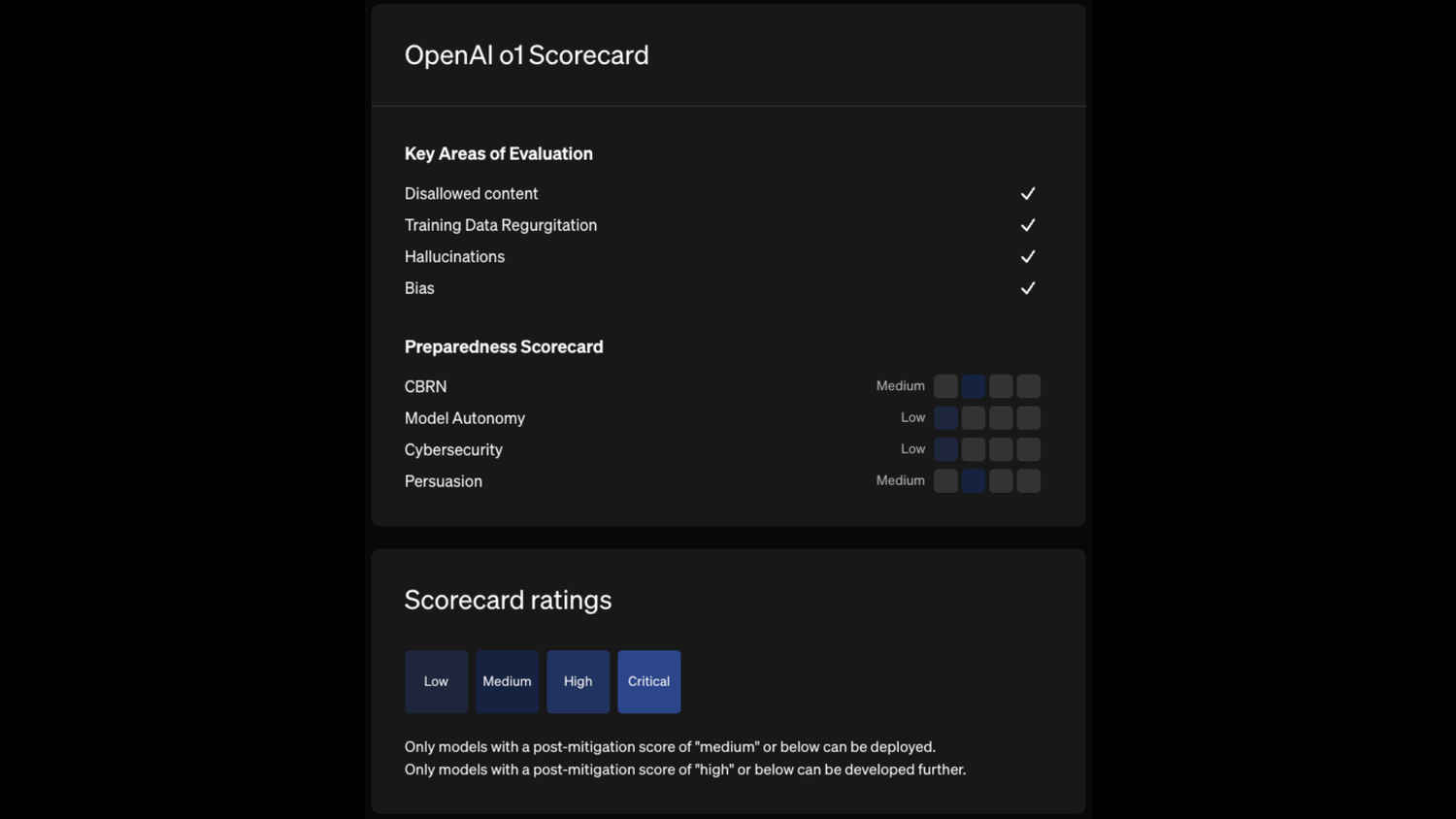
Reinforcement learning using chain of thought – OpenAI’s secret sauce
One of the key differentiating factors for OpenAI’s new model, o1 is its ability to closely mimic the human process of a problem’s evaluation using a chain of thought. To ensure that the model retains its claimed high accuracy levels, OpenAI has introduced the methodology of reinforced learning for the model. With this, the model is able to identify and learn from its mistakes and also zero in on the most effective strategies for generating responses.
In the demonstration published by OpenAI in the release document for the new model, they showcased how the new model formed a series of rather original evaluations of the problem that was presented to it in a prompt, broke it down into simpler segments and then produced a response that it thought would be the most accurate for its user.
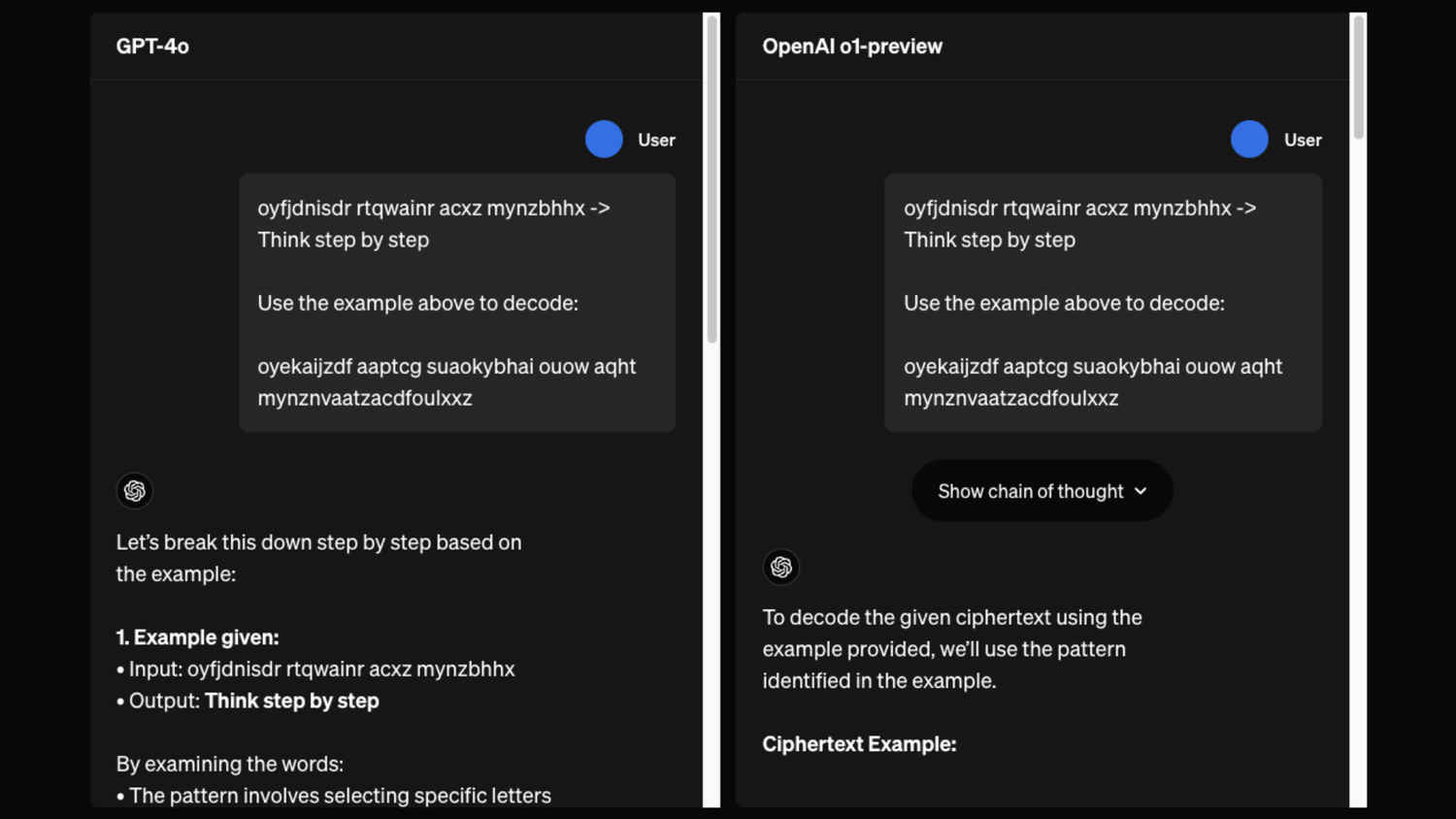
This ties into our next two points, which are about the increased accuracy of model o1 to open-ended prompts and reasoning queries.
Better response to open-ended prompts — That’s what the humans say
During the development of the new model, OpenAI tested the efficacy of model o1 when working with open-ended prompts. Not all of us are prompt engineers. If you have worked with generative AI models that are available today, you would know that, more often than not, open-ended prompts are not handed well by the existing models. After generating a response with an open-ended prompt, users are forced to refine the response by feeding in follow-up prompts.
With model o1, OpenAI claims that the responses generated by the model in response to open-ended prompts are preferred by humans over the ones generated by GPT-4o. However, we hit a roadblock when it comes to natural language processing and related applications, as OpenAI, in their documentation, mentioned – “o1-preview is not preferred on some natural language tasks, suggesting that it is not well-suited for all use cases.”
Strawberry has increased accuracy in reasoning queries
After thoroughly testing model o1, OpenAI concluded that the new model is consistent with generating more accurate results with respect to reasoning queries. The model apparently even outperformed human experts in certain benchmarks that were run while evaluating the model. These benchmarks spanned across multiple fields that have been pioneered by humans, including the likes of chemistry, physics and biology.
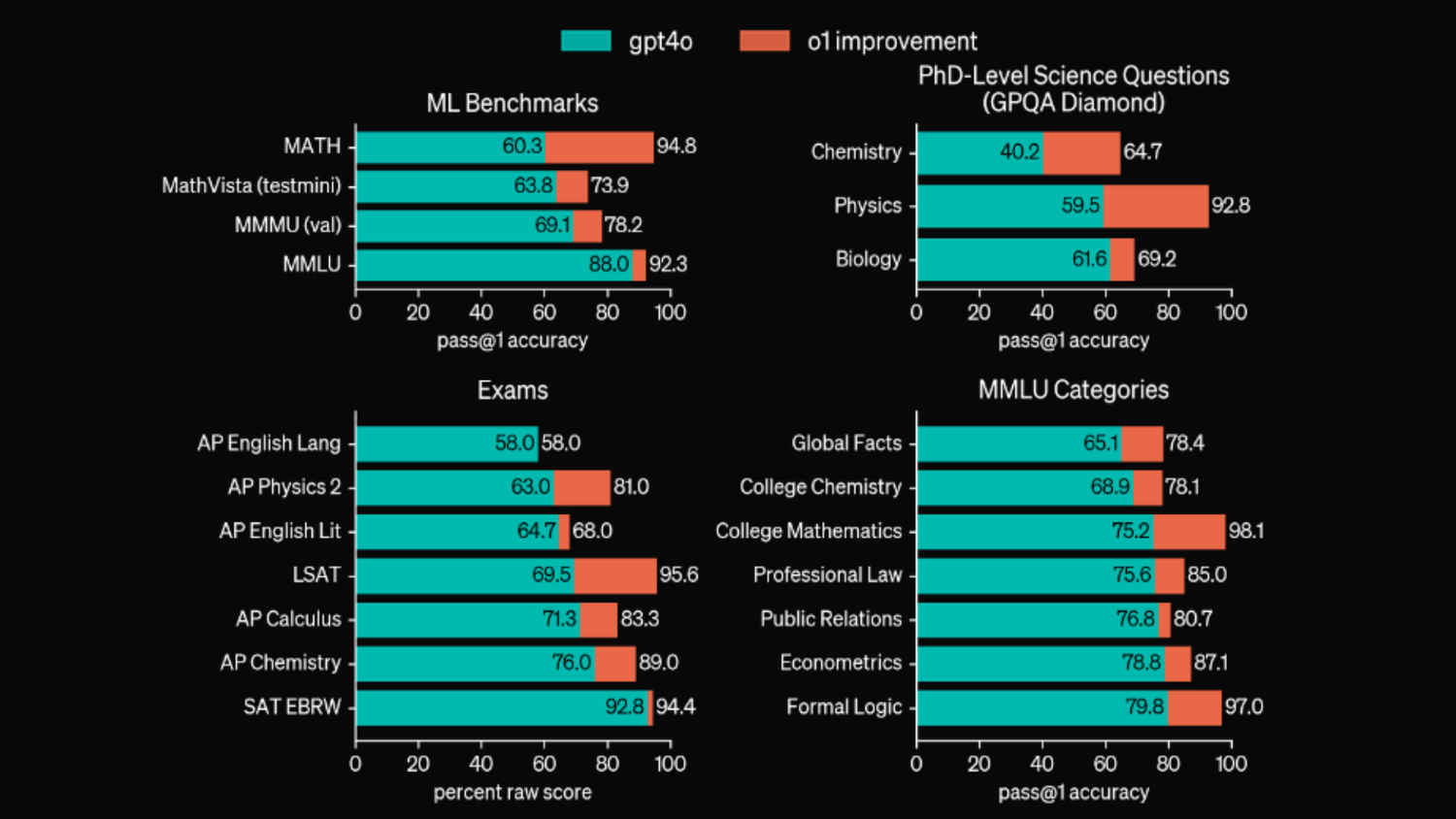
Not to mention, model o1 is better than GPT-4o in reasoning-heavy tasks. To back this claim, OpenAI has mentioned that the GPT-4o was able to solve an average of 12 per cent (1.8/15) of problems in the 2024 American Invitational Mathematics Examination (AIME). When working with a single sample per problem in the same set of questions, model o1 maintained 74 per cent accuracy, answering 11.1 correctly out of the 15 it was presented with. When the sample set was expanded, the model achieved an accuracy of up to 93 per cent.
Also Read: With iPhone 16’s camera button, is Apple betting iPhone’s future on photography alone?
Strawberry is a better coder than you are
In the benchmarking done by OpenAI, Strawberry achieved an ELO of 1807 compared to the 808 achieved by 4o. Open AI went a step ahead and trained a model to participate in a simulation run of the 2024 International Olympiad in Informatics (IOI), where it was pitted against human contestants and had ten hours to solve six algorithmic problems with the submissions for each problem being limited to 50. When the tests were run, model o1 was able to rank in the 49th percentile with a score of 213 points to its name.
The documentation about the model dives further into the strategy it employed during the run: “For each problem, our system sampled many candidate submissions and submitted 50 of them based on a test-time selection strategy. Submissions were selected based on performance on the IOI public test cases, model-generated test cases, and a learned scoring function. If we had instead submitted at random, we would have only scored 156 points on average, suggesting that this strategy was worth nearly 60 points under competition constraints.”
What’s next in the future of OpenAI Model o1?
The increased capabilities of model o1 over its predecessor, as OpenAI tries to perfect it, opens doors to a future that would seem rather scary on the surface; however, when you dive deeper, it has a sea of possibilities. If models like this are able to perform with increased efficiency and consistency, a lot of data-driven evaluation and problem-solving tasks across fields of research and development could be off-loaded to an AI model, as humans divert their attention towards tasks that would involve critical thinking by humans.
Satvik Pandey
Satvik Pandey, is a self-professed Steve Jobs (not Apple) fanboy, a science & tech writer, and a sports addict. At Digit, he works as a Deputy Features Editor, and manages the daily functioning of the magazine. He also reviews audio-products (speakers, headphones, soundbars, etc.), smartwatches, projectors, and everything else that he can get his hands on. A media and communications graduate, Satvik is also an avid shutterbug, and when he's not working or gaming, he can be found fiddling with any camera he can get his hands on and helping produce videos – which means he spends an awful amount of time in our studio. His game of choice is Counter-Strike, and he's still attempting to turn pro. He can talk your ear off about the game, and we'd strongly advise you to steer clear of the topic unless you too are a CS junkie. View Full Profile