Imagine asking a single assistant to schedule your meetings, design your presentation, and help your kid with algebra homework—all in one seamless interaction. Welcome to 2024, where AI became less of a tool and more of a collaborative partner. With the rise of multimodal AI, we moved beyond the clunky, single-mode systems of the past. Today, you don’t just talk to your AI—you gesture, type, upload, and even glance, creating a symphony of inputs that delivers results faster, smarter, and more intuitively than ever.
From Google Assistant’s ability to interpret a photo, a question, and a follow-up voice command all at once, to Apple’s Vision Pro blurring the lines between reality and augmented brilliance, multimodal AI has redefined how we work, play, and create. The evolution isn’t just technological; it’s cultural, reshaping industries from education and healthcare to content creation and gaming.
So how did we get here, and what does this all mean for our day-to-day lives? Let’s dive into the innovations that have turned once-disparate modalities into a unified, dynamic experience, bringing us closer to the AI-driven future we’ve only imagined.
Google made significant strides in multimodal AI with enhancements to Google Assistant. Earlier iterations of the Assistant relied heavily on singular modes of interaction, such as voice commands or text inputs, which often limited user engagement. In contrast, the advancements introduced in 2024 marked a pivotal evolution, enabling seamless integration across voice, text, and image inputs.
This innovation addressed previous constraints by creating a cohesive and dynamic user experience, exemplifying the leap from isolated functionality to a truly multimodal ecosystem. In 2024, it introduced seamless switching between voice, text, and image inputs. This allowed users to engage with tasks such as searching for information, scheduling events, and controlling smart devices without switching interfaces. For example, a user could start a query by typing, augment it by uploading an image, and finalize the interaction through a voice command. This integration leveraged advanced natural language processing and computer vision, creating a unified user experience.
Also Read: How AI hardware advanced privacy debate in 2024
Google Assistant also introduced context-aware functionality. For instance, users could point their smartphone camera at a restaurant menu, receive detailed dish descriptions, and simultaneously book a table through voice commands. This cohesive ecosystem emphasized user convenience, reducing friction in multitasking scenarios.
Microsoft expanded its Copilot feature across its Office suite, making multimodal interactions central to productivity tools. Users could now utilize text, voice, and visual inputs in applications like Word, Excel, and PowerPoint. This feature empowered professionals to create documents and presentations efficiently by combining modalities. For instance, a user could dictate a report’s introduction, upload charts via visual input, and refine formatting through textual instructions.
The integration of image generation in PowerPoint allowed users to describe a visual concept verbally, prompting the AI to generate relevant slides automatically. This eliminated the need for external design tools, streamlining workflows. Furthermore, by leveraging Azure’s AI capabilities, Copilot’s multimodal features extended beyond Office, enhancing collaborative platforms like Teams with real-time transcription and visual summarization of discussions.
Apple’s Vision Pro headset in 2024 represented a convergence of multimodal AI and augmented reality, profoundly impacting industries such as design, education, and healthcare. For instance, architects benefited from the ability to manipulate 3D building models with gestures while providing spoken input for specifications. In education, students used eye-tracking to navigate immersive virtual labs, enabling hands-on learning in subjects like chemistry and engineering.
Healthcare professionals leveraged the headset for augmented reality-assisted surgeries, combining gesture-based control with verbal guidance. These advancements underscored the headset’s ability to bridge virtual and real-world applications, setting new benchmarks for immersive technology. By integrating gesture recognition, voice commands, and eye-tracking, Vision Pro offered an immersive interface where users could interact with both virtual and real-world objects. For example, users could manipulate 3D models with hand gestures, dictate annotations, and navigate menus through gaze.
Also Read: Mixed reality in 2024: Best smart glasses, AR-XR headsets that made a mark
This system utilized Apple’s Neural Engine to process multimodal inputs in real time, ensuring seamless interactions. The device’s ability to overlay digital content on physical environments also enabled unique applications, such as virtual workspaces where users could arrange digital documents using gestures while speaking commands to organize files.
Amazon enhanced Alexa’s capabilities by introducing visual search, allowing users to identify objects by pointing a camera. For instance, scanning a book cover with a smartphone would prompt Alexa to provide details about the author, reviews, and purchase options. This feature complemented Alexa’s verbal query system, creating a hands-free, multimodal interaction.
In smart home settings, Alexa’s multimodal functionality extended to appliance control. Users could visually identify devices through a smartphone’s camera, with Alexa providing setup guidance via voice. This dual-modal approach reduced onboarding time for new smart devices, enhancing user accessibility.
Meta’s advancements in multimodal AI focused on personalising social media experiences, particularly for content creators and social media users who rely heavily on engagement metrics. For example, Meta’s AI models combined text and image analysis to recommend content tailored to individual preferences, increasing user retention by an average of 23%, according to internal studies. In 2024, users uploading photos with captions received automated hashtags and suggestions for enhancing image composition, with over 78% of surveyed users reporting improvements in audience reach.
Also Read:
Meta also introduced tools for content creators, enabling multimodal storytelling. Creators could input text and visuals to generate cohesive multimedia posts, which studies showed resulted in a 35% higher engagement rate compared to traditional posts. This integration highlighted Meta’s commitment to blending creative expression with AI-driven personalisation, benefiting marketers, influencers, and casual users alike. In 2024, Meta’s AI models combined text and image analysis to recommend content tailored to individual preferences. For example, users uploading photos with captions received automated hashtags and suggestions for enhancing image composition.
Meta also introduced tools for content creators, enabling multimodal storytelling. Creators could input text and visuals to generate cohesive multimedia posts. This integration highlighted Meta’s commitment to blending creative expression with AI-driven personalisation.
AI-driven content creation reached new heights with DeepAI’s animation tools. In 2024, creators could generate high-quality animation sequences by combining voice and visual prompts. For instance, describing a scene verbally and uploading character sketches allowed the AI to produce fully animated clips. This feature democratized animation, making it accessible to individuals without traditional skills in the field.
DeepAI’s speech-to-animation capability enabled real-time character lip-syncing, where characters animated themselves in response to spoken dialogue. For instance, this technology was employed in gaming to create non-playable characters (NPCs) that dynamically interacted with players’ speech, enhancing immersion. In digital marketing, animated mascots responded to customer inquiries in real time, providing an engaging and personalized user experience. This technology found applications in gaming, education, and digital marketing, reducing production time and costs significantly.
Runway’s video editing platform introduced features supporting both visual prompts and text-based manipulations. Users could describe a scene in writing, such as “a sunset over a bustling city,” and the AI would generate corresponding video clips. Additionally, users could refine existing videos by providing visual references, allowing for stylistic consistency.
Also Read: How SLMs made AI more compact and powerful in 2024
The tool’s ability to analyze visual inputs and apply effects automatically simplified complex editing tasks. For instance, a filmmaker could upload a storyboard, and the AI would assemble raw footage into a draft sequence, aligning shots with the intended narrative.
OpenAI’s DALL·E 3 expanded its creative capabilities by accepting both textual and visual prompts. Users could input an image and a descriptive text to guide the generation of new artwork. This feature enabled iterative design processes, where users refined outputs by combining ideas from multiple sources.
For example, designers could upload a rough sketch and specify details like “refine texture to resemble marble,” resulting in polished, high-resolution renders. This multimodal input capability made DALL·E 3 a versatile tool for artists, architects, and marketers.
Aiva AI pushed the boundaries of music composition by integrating multimodal inputs. Musicians could describe a desired mood, such as “calm and introspective,” and supplement it with an image evoking that emotion. The AI used these inputs to generate original compositions, blending melody, harmony, and instrumentation tailored to the user’s vision.
This approach bridged the gap between traditional and digital artistry, empowering creators to explore new genres and styles. It also catered to content creators seeking royalty-free music customized to their projects.
Descript’s Overdub feature revolutionized podcast creation by combining text-based inputs with voice synthesis. Users could type topics, and the AI generated voiceovers that matched the tone and pacing of the speaker’s prior recordings. This capability allowed for rapid prototyping of podcast episodes.
Overdub’s integration with real-time editing tools enabled seamless adjustments. For instance, creators could modify scripts mid-production, with the AI updating the voiceover instantly. This efficiency reduced production timelines while maintaining high-quality output.
Meta’s 2024 chatbots featured multimodal interactions, combining text, voice, and image inputs. Users could engage in conversational queries while sharing visual content for analysis. For example, uploading a photo of a product during a chat would prompt the AI to provide reviews, pricing, and availability.
These chatbots also supported personalized responses. By analyzing user preferences and behavior, the AI delivered contextually relevant recommendations, enhancing user satisfaction.
Google Assistant and Amazon Alexa deepened their multimodal integrations with smart home devices. In 2024, these assistants provided feedback through voice prompts, on-screen visuals, and haptic vibrations. For example, Alexa’s smart displays offered step-by-step cooking instructions, combining verbal guidance with visual timers and video demonstrations.
This multimodal feedback improved accessibility for users with diverse needs. Haptic cues on smart displays aided users with hearing impairments, while detailed visuals supported those unfamiliar with verbal instructions.
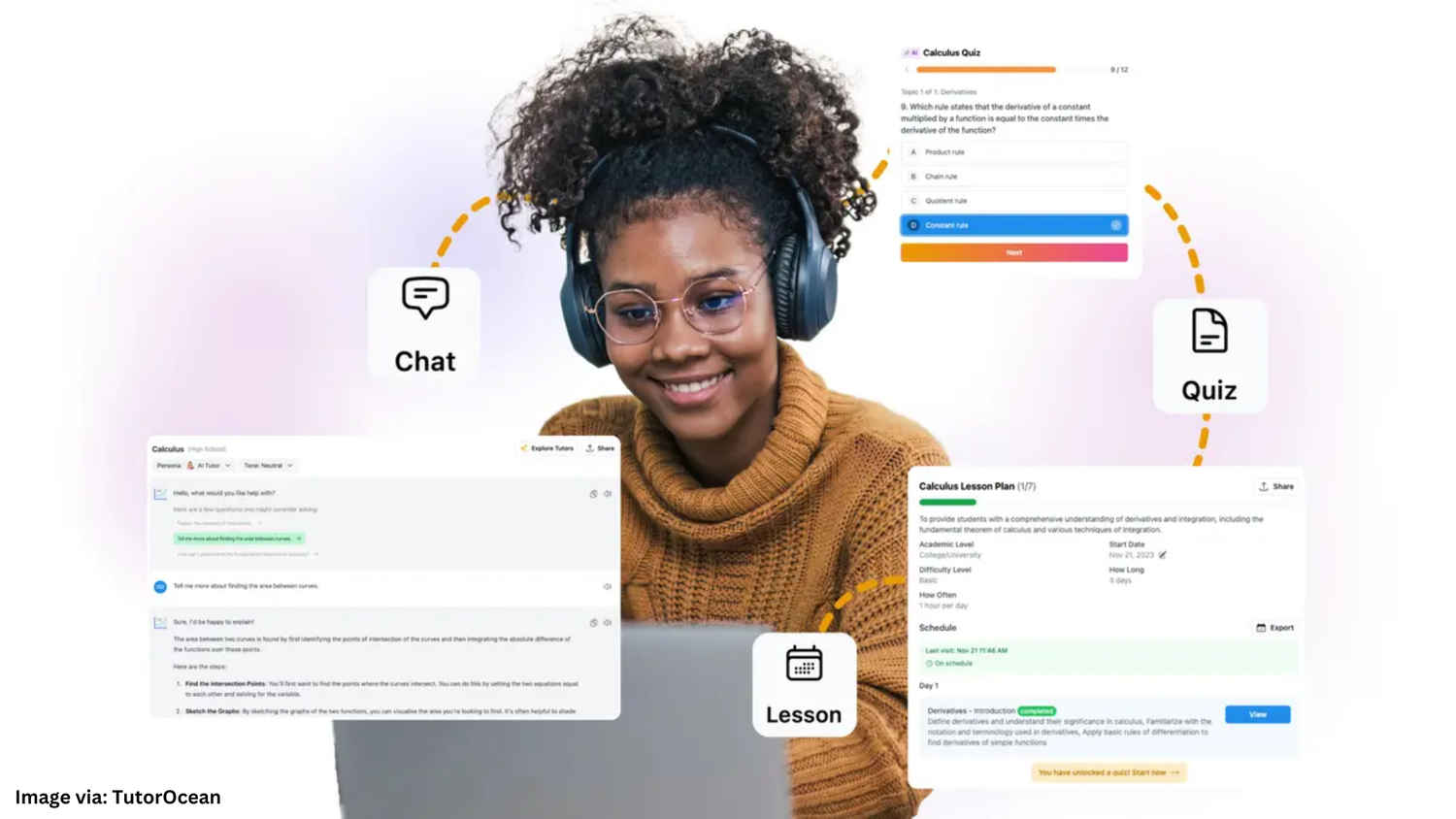
AI-powered learning platforms like Khan Academy introduced tools for multimodal education. These tools have proven especially effective in subjects like mathematics, science, and language arts at both secondary and higher education levels. Students could interact with AI tutors through spoken queries, written notes, and visual aids such as graphs and diagrams. For instance, a student struggling with algebra could receive step-by-step explanations in text, accompanied by animated visualizations.
These systems also adapted to individual learning styles, offering tailored feedback and resources. In real-world applications, they have been used to address gaps in remote learning by providing personalized attention and supplementary resources to students in underprivileged areas.
Also Read: Apple in 2024: From Apple Intelligence to Vision Pro, Apple did push some boundaries this year
By combining modalities, they provided a more engaging and effective educational experience. AI-powered learning platforms like Khan Academy introduced tools for multimodal education. Students could interact with AI tutors through spoken queries, written notes, and visual aids such as graphs and diagrams. For instance, a student struggling with algebra could receive step-by-step explanations in text, accompanied by animated visualizations.
These systems also adapted to individual learning styles, offering tailored feedback and resources. By combining modalities, they provided a more engaging and effective educational experience.
SpaceMaker AI brought innovation to architecture by supporting multimodal design inputs. Architects could describe concepts verbally, sketch ideas, and upload reference images. The AI synthesized these inputs to generate comprehensive building designs, factoring in environmental considerations like light, noise, and energy efficiency.
This approach streamlined the iterative design process, enabling architects to explore multiple configurations quickly. It also supported collaboration by visualizing designs in real time, facilitating client feedback.
Narrative-driven platforms like ChatGPT Stories offered collaborative storytelling experiences. Users could provide prompts in text, voice, or images, and the AI generated subsequent story elements. For instance, a user could upload a landscape photo and request a plot set in that environment, with the AI crafting characters and events accordingly.
This multimodal interaction fostered creativity, allowing users to explore diverse narrative possibilities. It also catered to educators and game developers seeking dynamic, interactive content.
Also Read: From AI agents to humanoid robots: Top AI trends for 2025
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}