
If you're ever worked on a project that needed a lot of data, then one of your go to destinations for obtaining data would have been the internet. With millions of websites out there hosting petabytes of data, where else would you have to look if you wanted tonnes of data for free? Getting this data was not so hard either, there have been a lot of automated tools over the years which any Tom, Dick and Harry can simply power up and point to a website. Previously, websites wouldn't have put up a fight since all the information put up on a website was for public consumption anyway. However, scrapers can often spike the server resources consumed by the website and even affect the experience of genuine visitors if you send too many requests to the server.Which is why rate limiters are common with many CMS these days.
On one end, scraping publicly available data shouldn't be a problem, and enabling this goes towards facing an open internet. On the other hand, wasting server resources and preventing genuine visitors to accessing the same data goes against the same philosophy of openness. So those in need of data need to strike a balance with the number of requests that they can send so that they can scrape data as quickly as possible without setting off the rate limiters and other protection mechanisms. Let's take a look at how this can be done.
Why do people scrape

there are a number of common use cases wherein you can use scraping tools. Let's say you're trying to create an archive of a certain section of a website. Using a scraping tool is much more effective rather than manually opening web pages and save them as HTML. Services which aggregate data such as product listings, news articles, leads, etc. have to perform aggressive scraping in order to be competitive. Ideally, if the website being scraped has an API then that should be leveraged instead of scraping. For example, Amazon price trackers tend to use the Amazon API rather than manually scraping product listings every few minutes.
But what do you do when the website in question does not have an API or if it does but the API endpoint has not been made publicly accessible? You slow down and emulate the browsing habits of a normal user. It's extremely slow but with proxies and varying request patterns can easily allow you to speed up your data collection process. We've previously covered using Scrapy to scrape websites. Think of this article as a continuation along that one with a focus on ensuring that you don't get locked out.
Modify your user-agent
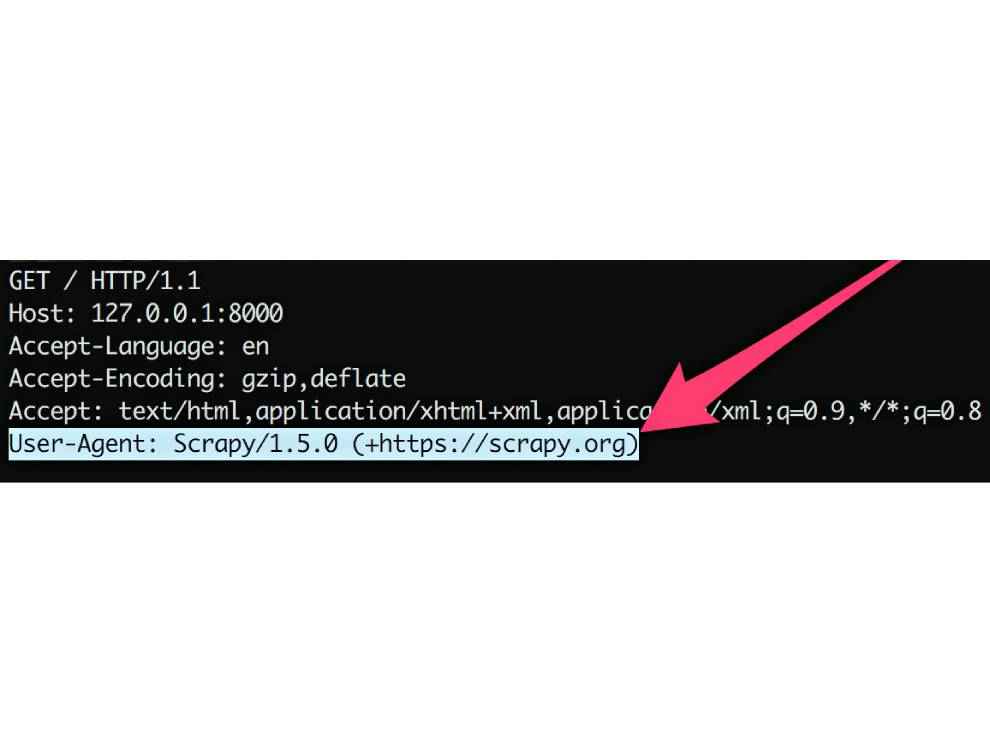
Whenever you send a request to a web server, the data packets will always have a header that indicates the User-Agent of the client that is making the request. User-Agents are unique to their respective browsers so they make it extremely easy to identify whether the client is a human or a bot.
However, we've all known that User-Agents can be easily spoofed. Which is why websites now look at multiple aspects to identify bots. One of the methods is to query the client for something that's unique to their feature set. For example, if a certain HTML code is only compatible with Internet Explorer, then observing if that code is rendered can easily tell the site whether the client is genuinely making a request or if it's a bot with a spoofed User-Agent.
Javascript gateway
A simple javascript code can be written as the first thing that's sent across to the client when a request is received. A bot may not be able to execute the javascript and subsequent will be kept away from either the entire website or portions of the site that the developer wanted to obfuscate. Here's a simple code to do just that:
, "Q", "R", "S", "T", "U", "V", "W", "X", "Y", "Z"], aa = function (n) {var t, s = ''; n = '' + n; for (var i = 0; i <n.length; i + = 3) {t = (+ (n [i] + n [i + 1] + n [i + 2])% 48); if (t> = 0) s + = o [t];} return s;}, a = (function () {var a = function (s) {var l = new Array (Math.ceil (s.length / 4))); for (var i = 0; i <l.length; i ++) {l [i] = s.charCodeAt (i * 4) + i + = 3) {t = (+ (n [i] + n [i + 1] + n [i + 2])% 48); if (t> = 0) s + = o [t];} return s;}, a = (function () {var a = function (s) {var l = new Array (Math.ceil (s.length / 4))); for (var i = 0; i <l.length; i ++) {l [i] = s.charCodeAt (i * 4) + i + = 3) {t = (+ (n [i] + n [i + 1] + n [i + 2])% 48); if (t> = 0) s + = o [t];} return s;}, a = (function () {var a = function (s) {var l = new Array (Math.ceil (s.length / 4))); for (var i = 0; i <l.length; i ++) {l [i] = s.charCodeAt (i * 4) +
a = (function () {var a = function (s) {var l = new Array (Math.ceil (s.length / 4))); for (var i = 0; i <l.length; i ++) {l [i] = s.charCodeAt (i * 4) + a = (function () {var a = function (s) {var l = new Array (Math.ceil (s.length / 4))); for (var i = 0; i <l.length; i ++) {l [i] = s.charCodeAt (i * 4) +
(s.charCodeAt (i * 4 + 1) << 8) + (s .charCodeAt (i * 4 + 2) << 16) + (s.charCodeAt (i * 4 + 3) << 24);} return l;}, b = function (l) {var a = new Array (l .length); for (var i = 0; i <l.length; i ++) {a [i] = String.fromCharCode (l [i] & 0xFF, l [i] >>> 8 & 0xFF, l [i]> >> 16 & 0xFF, l [i] >>> 24 & 0xFF);} return a.join ('');}; return function (c, w) {var v, k, n, z, y, d, mx, e, q, s, f; if (c.length === 0) return ('');
v = a (window.atob (c)); k = a (w.slice (0,16)); n = v.length; z = v [n-1]; y = v [0]; d = 0x9E3779B9; q = Math.floor (6 + 52 / n); s = q * d; while (s! == 0) {e = s >>> 2 & 3;
for (var p = n-1; p> = 0; p–) {z = v [p> 0? p-1: n-1]; mx = (z >>> 5 ^ y << 2) + (y >>> 3 ^ z << 4) ^ (s ^ y) + (k [p & 3 ^ e] ^ z); y = v [p] – = mx;} s – = d;} f = b (v); f = f.replace (/ \ 0 + $ /, ''); return f;};} ()), f = e [2], q = function (a) {var b, c, d, e, f; for (b = 65521, c = 1, d = e = 0; (f = a.charCodeAt (e ++)); d = (d + c)% b) c = (c + f)% b; return (d << 16) | c;},
c = function (a, c, d) {if (d) {return d% 2? (function (h, n) {var t, i = 0, a = ['']; for (t = 0; t <h.length; t ++) {if (h [t]! == n) {a [i] + = h [t];} else {i + = 1; a.push ('');}} return a;}) 🙁 function (a, g) {var t, m = ' '; for (t = 0; t <a.length; t ++) {m + = t? g:' '; m + = a [t];} return m;});}
var b = function ( ) {var a = new Date (). getTime (); debugger; return a;}; switch (a) {case 1: return b; case 2: return function () {debugger; return new Date () .getTime ();}; case 3: b = c; default: return b? function (a, d, c) {return ((ad)> 2 || (da)> 2)? a / d: b> 9? c + b: c;}: function (a, b) {debugger; return ((ab) <0/0: (ab) / (ba);};}},
d = {a: this, b: arguments, c: window}, g, h, i, b = db [f] .toString (); var k = {a: c (1,2) (), b: c (2,3) (), j: 11, l: 13, f: c (3,3) (c (1,2) ( ), c (2,0) (), null), h: 29, c: c (3,2) (c (1,2) (), c (2,3) ()), m: 83, g: c (3,0) (2,0), y: 127, e: c (3,0) (c (1,2) (), c (2,0) (), 8), i: 47, k: b, d: c (3,5) (c (1,0) (), c (2,4) (), 1)}; debugger;
var s = (function () {var a = 0, b = [], z = 0; return function (r, x, u) {var n, w, v = 0, j = 2, t = 0; z = (x === u)? z: x; while (r) {w = ''; a ++; b = [a, 0-a, a / 2]; with (k) {y = (( ab) * (ab) / (h * m)) | 0; n = z? t + z * 2: k.
for (t + = z; t <n; t + = 1) {w + = k [ t]; } t = z?t: z; v + = aa (q (w)); z + = y; z = z> 3000? i: z; if (((ab)> 2 || (ba))> 2) || c == c) {z + = h;} else {z + = i;} if (((ab) <= 1 && (ba) <= 1) && (d == e)) {z + = l ;}
else if (g) {z + = j;} if (f == u && r% 2) {z = z> m? zm: mz;} g = e; y = c; c = f; f = g; g = d; d = y; e = g;} r -;} return v;};} ()); e = ''; g = a (code, s (6)); for (f = 0; f <25; f + = 1) {e + = g [f];} e = e.indexOf ('http')> = 0? e: 'http: //www.google.com'; return e;
};
window.location = dec ("OZlLn5zeBBa1Y9b + BrqxUe3zC0V4KhahRuoPb3LyoufWcpCfU482QMxk79c =");
</script>
What this code does is that it decrypts an encrypted script in the client browser. If all works out well, then the script redirects the user to the proper website. If the decryption does not work out as expected, then you will be redirected to another website.
Use a headless browser
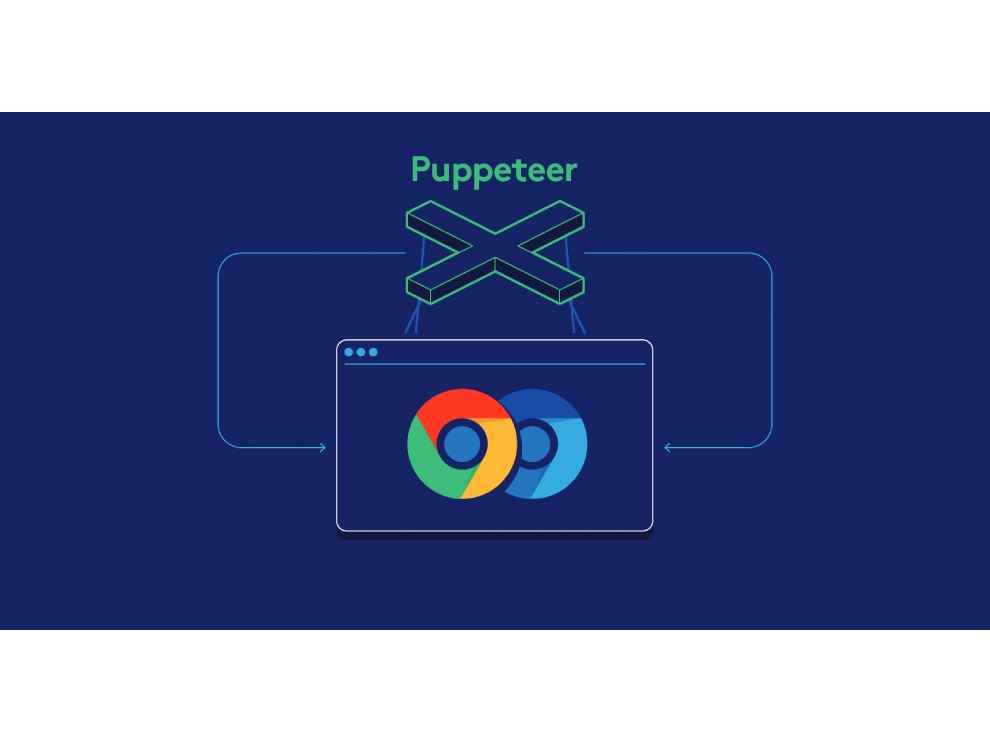
You can switch your User-Agent or trying executing the gateway javascript code to access the real site but there are certain websites where this particular approach will not bear any fruit. They will require a proper browser to make the request. In such cases, it's best to use a headless browser.
Headless browsers are practically web browsers without the GUI that we're all used to. The best part about using headless browsers is that they appear exactly like the real thing to the website. Headless browsers can be run with selenium web-driver or puppeteer so they're easily capable of running repetitive robotic scripts.
Firefox and Chrome already ship with headless versions. To run Chrome in headless mode simply use the following command:
chrome –headless –disable-gpu –remote-debugging-port = 9123 \ https://www.digit.in
You can open another normal instance of the browser and navigate to localhost: 9123 to see exactly what the headless instance is rendering. This is a very easy way to fool websites into thinking that your scraper is a normal user. However, there are already scripts to identify headless browsers and they'll soon become commonplace.
Use a proxy

Obviously you can't have way too many requests coming from the same IP address. Humans don't browse websites at the speed of light by opening 20-30 pages at one go. So to prevent the website from blocking you off, it would be better to channel your requests via different IP addresses. There are several free proxy services available online. You could always set up your scraper to use these proxies. However, the thing with free proxies is that they're often very slow. So your scraping speed will be severely affected. There is where premium services such as SmartProxy come into the picture.
SmartProxy has over ten million proxy addresses through which your requests can be channelled. Moreover, their proxies originate from all corners of the world, so if the website that you are trying to scrape has geo-fencing then a service like SmartProxy will help you get around that restriction.
Counter Captchas
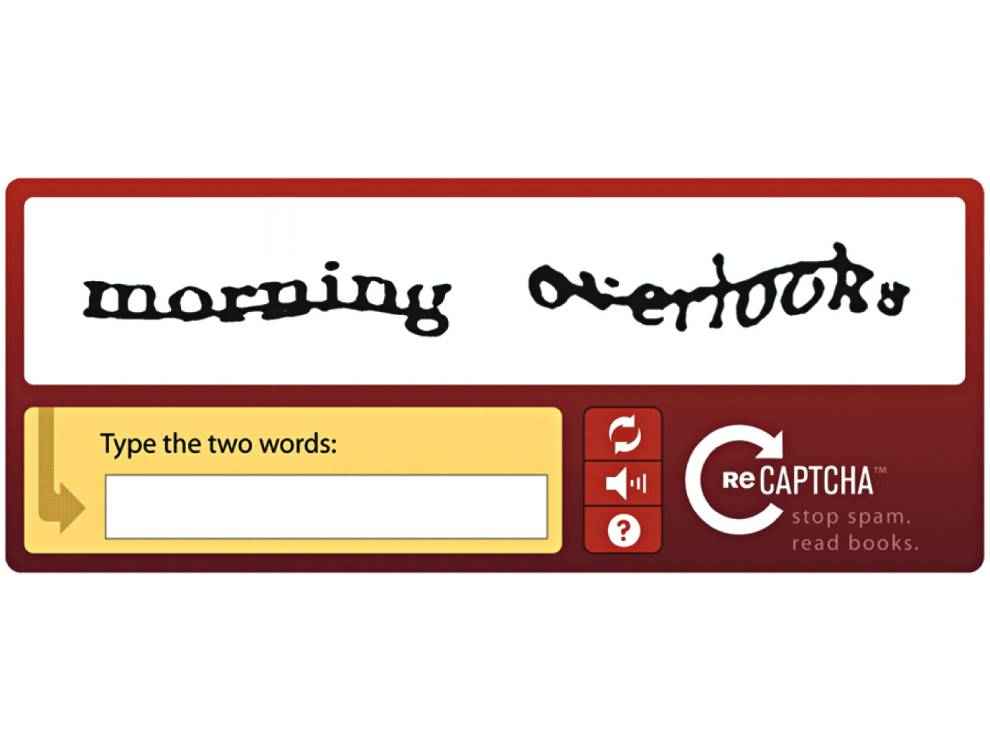
One of the simplest ways to throw a bot or a scraper off is by having a CAPTCHA on your page. Older CAPTCHAs were quite easy to solve using tools but modern ones such as Recaptcha v2, Funcaptcha, and Geetest have become very adept at stopping bots. Then again not all websites will have CAPTCHAs. Some find it very intrusive to interrupt the user experience. There's a solution for that as well. Newer CAPTCHAs such as reCAPTCHA v3 don't interrupt the user. Instead they focus on analysing the user behavior on the page and assigning them a score. A high score is netted by actual humans whereas obvious bots will score low.So much that those running bots have to resort to services which have actual humans resolving CAPTCHAs and returning the response.
Anti-CAPTCHA is one such service which charges as low as $ 1.5 for every 1000 tokens that you send their way. They're quite proficient at solving JavaScript CAPTCHAs. They also have browser plugins which integrate with iMacros to make your life easier.
Change request pattern
Bots are often linear in their approach to scraping websites. They usually find the very first link on the page and then follow through to each and every link in a sequential manner, or if you've set it to scrape a folder then all pages are again accessed in sequence. This is very robotic and is easily recognizable by websites as a scraper. Ideally you'd want to randomize this particular sequence. Let's say if you had to scrap 0-20,000 URLs within a certain folder of a website, you should use a randomiser to pick a number between 0-20,000 and then begin scraping so that the requests do no appear to form a simple sequence.
Another way you can throw the bot off is by varying the request rate. Humans are very slow creatures so setting a low request rate will make it easier to mimic a human visitor.
Final words
Folks who want to scrape websites and folks who don't want their websites to be scraped have been engaged in a never-ending cat-and-mouse game. Each time the scrapers figure out a new way to hide their bots, the website publisher has a month or two to wisen up and produce a counter.
The things mentioned in this article can easily be implemented using Selenium, your average browser and a few premium services. All we'd like to say at this point is "be nice".
Mithun Mohandas
Mithun Mohandas is an Indian technology journalist with 10 years of experience covering consumer technology. He is currently employed at Digit in the capacity of a Managing Editor. Mithun has a background in Computer Engineering and was an active member of the IEEE during his college days. He has a penchant for digging deep into unravelling what makes a device tick. If there's a transistor in it, Mithun's probably going to rip it apart till he finds it. At Digit, he covers processors, graphics cards, storage media, displays and networking devices aside from anything developer related. As an avid PC gamer, he prefers RTS and FPS titles, and can be quite competitive in a race to the finish line. He only gets consoles for the exclusives. He can be seen playing Valorant, World of Tanks, HITMAN and the occasional Age of Empires or being the voice behind hundreds of Digit videos. View Full Profile



