
Introduction
This example demonstrates the creation of a texture in OpenGL* 4.3 that has a sub-region updated by an OpenCL™ C kernel running on Intel® Processor Graphics with Microsoft Windows*. One example use of this is for a real-time computer vision applications where we want to run a feature detector over an image in OpenCL but render the final output to the screen in real time with the detectors clearly marked. In this case you wants access to the expressiveness of the OpenCL C kernel language for compute but the rendering capabilities of the OpenGL API for compatibility with your existing pipeline. Another example might be a dynamically generated procedural texture created in OpenCL used as a texture when rendering a 3D object in the scene. Finally, imagine post processing an image with OpenCL after rendering the scene using the 3D pipeline. This could be useful for color conversions, resampling, or performing compression in some scenarios.
This sample demonstrates updating a texture using OpenCL that was created in OpenGL. The same recommendations apply to update to a vertex buffer or an off-screen framebuffer object that might be used in a non-interactive offline image processing pipeline.
The surface sharing extension is defined in the OpenCL extension specification with the stringcl_khr_gl_sharing. We also leverage the extension cl_khr_gl_event that is supported on Intel processor graphics.
Motivation
This tutorial purpose is to help you understand how to create shared surfaces between OpenCL and OpenGL. It’s also to help you understand the APIs as well as the performance implications of the texture creation paths in the OpenGL API, in particular on Intel processor graphics and how this might be different than discrete GPUs when sharing surfaces.
Key Takeaway
To create an OpenGL texture and share it as an OpenCL image and get the best performance on Intel processor graphics do not create an OpenGL pixel buffer object (PBO). PBOs have no performance benefit on Intel processor graphics. Additionally, they create at a minimum an additional linear copy of the data which is then copied to the tiled texture format that is actually used by the GPU for rendering. Secondly, instead of using a glFinish() to synchronize between OpenCL and OpenGL we can use the implicit synchronization mechanism between OpenCL and OpenGL with Intel processor graphics, which supports the cl_khr_gl_event extension.
Intel® Processor Graphics with Shared Physical Memory
Intel® Processor Graphics shares memory with the CPU. Figure 1 shows their relationship. While not shown in this figure, several architectural features exist that enhance the memory subsystem. For example, cache hierarchies, samplers, support for atomics, and read and write queues are all utilized to get maximum performance from the memory subsystem.
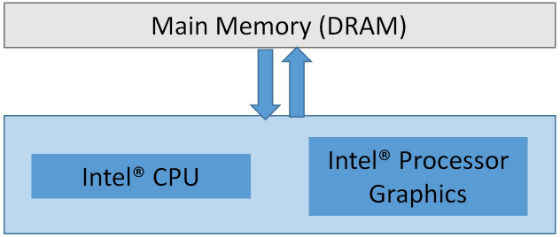
Figure 1. Relationship of the CPU, Intel® processor graphics, and main memory. Notice a single pool of memory is shared by the CPU and GPU, unlike discrete GPUs that have their own dedicated memory that must be managed by the driver.
Why not to use Pixel Buffer Objects (PBOs) on Intel Processor Graphics
The OpenGL specification encourages users to Pixel Buffer Objects when sharing between the CPU and the GPU:
From chapter 6 of the OpenGL Programming Guide:
“The primary advantage of using a buffer object to stage texture data is that the transfer from the buffer object into the texture need not occur immediately, so long as it occurs by the time the data is required by a shader. This allows the transfer to occur in parallel with the application running. If instead the data is located in application memory, then the semantics of glTexSubImage2D() require that a copy of the data is made before the function returns, preventing a parallel transfer. The advantage of this method is that the application is free to modify the data it passed to the function as soon as the function returns.”
Notice the focus of this API call is on sharing between the application memory (i.e., CPU memory) and the GPU, not the case of sharing between two APIs both executing their command streams on the same device with the same physical memory as shown in Figure 1.
PBOs actually decrease performance on devices that make use of shared physical memory. First, the PBO is an extra staging area which means additional memory consumption by the application. Second, the data is laid out linearly in a PBO, and if the data needs to be laid out in a tiled format as an OpenGL texture or an OpenCL image, then we have to swizzle the data between the respective formats. Finally, the time of a copy that would have to take place between the APIs will also negatively impact the performance of the application!
In the case of sharing with a discrete GPU using PBOs makes perfect sense: you can issue a DMA transfer that runs asynchronously with the CPU. Without a PBO, the OpenGL semantics require a synchronous write and thus wait for the result to return decreasing performance. In our case, there is no data transfer from the CPU to the GPU memory subsystem.
When might you want to use a PBO with surface sharing?
There are cases you might use a PBO. One example is when there is no suitable surface format between OpenGL and OpenCL from Table 9.4 in the OpenCL Extension Specification. In this case a PBO can be created and shared with the APIs associated with buffer sharing. However, try to avoid this scenario for performance considerations previously described. If this is needed, refer to Maxim Shevtsov’s sample in the references.
Synchronization between OpenCL™ and OpenGL*
At run time it is important to get the best performance between OpenCL and OpenGL. The specification states the following:
“Prior to calling clEnqueueAcquireGLObjects, the application must ensure that any pending GL operations which access the objects specified in mem_objects have completed. This may be accomplished portably by issuing and waiting for completion of a glFinish command on all GL contexts with pending references to these objects. Implementations may offer more efficient synchronization methods; for example on some platforms calling glFlush may be sufficient, or synchronization may be implicit within a thread, or there may be vendor-specific extensions that enable placing a fence in the GL command stream and waiting for completion of that fence in the CL command queue. Note that no synchronization methods other than glFinish are portable between OpenGL implementations at this time.”
For maximum portability the specification states you must call glFinish() which is a blocking call! On Intel processor graphics you can do better by using implicit synchronization or synchronization objects between OpenCL and OpenGL with the cl_khr_gl_events extension. This will be discussed in more detail below. It is not required to use the explicit synchronization. The sample code includes commented out segments that can be reintroduced if the programmer wants to use explicit synchronization.
Overview of Surface Sharing between OpenCL and OpenGL
First we present the steps to support surface sharing during initialization, runtime, and shutdown. Next, we give more detail including API and language syntax. Finally, we close with how these ideas can be extended to other surface formats not part of this example. We use the publicly available freeglut for window management as well as the glew library. The use of these libraries is standard practice for OpenGL sample applications and will not be described further.
Initialization
1. OpenCL:
1. Query to determine if the extension(s) is supported, exit if unsupported
2. Create the context passing the appropriate device options
3. Create a queue on the device in the context that supports sharing between OpenGL and OpenCL
2. OpenGL: Create an OpenGL texture to be shared with OpenCL
3. OpenCL: Using the OpenGL handle created in 2, create a shared surface via the OpenCL extension
Steps 1 and 2 can be interchanged. Step 3 must proceed steps 1 and 2.
Writing to the shared surface in OpenCL
1. Lock the surface for OpenCL exclusive access
2. Write to the surface via the OpenCL C kernel. In the case of texture data, be sure to use the image read and/or write functions and pass in the 3. image appropriately
3. Unlock the surface so that OpenGL may now read or write the surface
Steps 1, 2, and 3 must be done in order.
The Render Loop
The focus of this article is achieving sharing between the CPU and the GPU. The render loop uses a simple pass through a programmable vertex and a pixel shader to texture map two screen-oriented triangles that form a quadrilateral for display of the result. The quadrilateral does not take up the full screen to show the clear color through on the background of the rendering.
Shutdown
1. Cleanup the OpenCL state
2. Cleanup the OpenGL state
Details of surface sharing between OpenGL and OpenCL
This section gives the details of the steps described in the previous section.
Initialization
1. OpenCL:
1. Query to determine if the extension is supported, exit if unsupported
Not every implementation of OpenCL supports surface sharing between OpenCL and OpenGL, so the first step is to determine if the extension even exists on the system. We iterate through the platforms looking at the extension string for a platform that supports surface sharing. Careful reading of the specification highlights this is a platform extension not a device extension. Later, when we create a context we will have to query to determine which of our devices in the context can share with the OpenGL context.
This sample is only supported on Intel processor graphics but it should be trivial to expand the scope to other GPUs. The extension string we are looking for is cl_khr_gl_sharing. The relevant code snippet is:
01 char extension_string[1024];
02 memset(extension_string, '', 1024);
03 status = clGetPlatformInfo( platforms[i],
04 CL_PLATFORM_EXTENSIONS,
05 sizeof(extension_string),
06 extension_string,
07 NULL);
08 char *extStringStart = NULL;
09 extStringStart = strstr(extension_string, "cl_khr_gl_sharing");
10 if(extStringStart != 0){
11 printf("Platform does support cl_khr_gl_sharingn");
12 …
13 }
2. If supported, create a context passing the appropriate device options
If OpenCL supports surface sharing with OpenGL then we want to create an OpenCL context that contains support for this capability. On Windows we pass a handle to the current GL rendering context as well as the current device context. Note on other platforms different flags need to be passed into the runtime. Table 4.5 of the OpenCL Extension Specification contains descriptions of the rendering context flags that need passed to the clCreateContext() API. CL_WGL_HDC_KHR is for Windows 7 and Windows 8, on MacOS the flag would be CL_CGL_SHAREGROUP_KHR. There are several ways to obtain these values and you need to use the windowing API of the operating system documentation.
In the Windows example we use:
01 //get the GL rendering context
02 HGLRC hGLRC = wglGetCurrentContext();
03 //get the device context
04 HDC hDC = wglGetCurrentDC();
05 cl_context_properties cps[] =
06 {
07 CL_CONTEXT_PLATFORM, (cl_context_properties)platformToUse,
08 CL_GL_CONTEXT_KHR, (cl_context_properties)hGLRC,
09 CL_WGL_HDC_KHR, (cl_context_properties)hDC,
10 0
11 };
12
13 //create an OCL context using the context properties
14 g_clContext = clCreateContext(cps, 1, g_clDevices, NULL, NULL, &status);
3. Create a queue on the device in the context that supports sharing between OpenGL and OpenCL
We query the context for the device from a specific device that we plan to support sharing between OpenCL and OpenGL. Since we have already checked to make sure the extension is supported we can grab the pointer to the required extension:
1 clGetGLContextInfoKHR_fn pclGetGLContextInfoKHR = (clGetGLContextInfoKHR_fn)
2 clGetExtensionFunctionAddressForPlatform(g_platformToUse
Then query for the device ID that supports sharing between OpenCL and OpenGL:
1 devID = pclGetGLContextInfoKHR(cps, CL_CURRENT_DEVICE_
Finally, create the command queue for the application on this device:
1 //create an openCL commandqueue
2 g_clCommandQueue = clCreateCommandQueue(g_clContext, devID, 0, &status);
3 testStatus(status, "clCreateCommandQueue error");
Note the sample code is slightly different showing the required dance moves if you want to use it as a template to pass CL_DEVICES_FOR_GL_CONTEXT_KHR. For more details refer to the specification in section 9.5.5 as well as 9.5.6 Issue 7 and Issue 8 as well as another Intel sample listed in the references [Shevtsov 2014].
OpenGL: Create an OpenGL texture that we will share with OpenCL
2. In OpenGL we create the texture we will share with OpenCL. There are several ways to create a texture in OpenGL depending on how you want to update the data and the documentation of the OpenGL specification goes into the details. In this case we create a 2D texture, create storage for the texture, and either leave the data empty or initialize it. We will discuss some alternatives later.
01 //create a texture object and assign data to it
02 GLuint texture_object;
03 glGenTextures(1, &texture_object);
04 //bind the texture
05 glBindTexture(GL_TEXTURE_2D, texture_object);
06 //allocate storage for texture data
07 glTexStorage2D(GL_TEXTURE_2D, 1, GL_RGBA8, tex_width, tex_height);
08
09 //specify data
10 glTexSubImage2D(GL_TEXTURE_2D,
11 0, //mip map level, in this case we only have 1 level==0
12 0, 0, //subregion offset
13 tex_width, tex_height, //width and height of subregion
14 GL_RGBA, GL_UNSIGNED_BYTE,
15 texture); //works! We specify initial data
We omit the boilerplate OpenGL-specific API calls for filtering, wrapping, and mipmapping. These are shown in the accompanying sample code. Surface sharing between OpenCL and OpenGL does not currently support mipmaps and native mipmap support is a separate OpenCL extensioncl_khr_mipmap_image.
In this case we wanted to be as general as possible and specify a full RGBA surface to share between OpenGL and OpenCL because it provides the most general capability between the APIs. Also, we chose to use glTexSubImage2D() for generality in the event you only want to update a partial or the entire texture. We use this API to pass an initialized buffer to OpenCL to simulate the scenario of a surface that both OpenCL and OpenGL are writing to and demonstrate that the OpenGL writes are preserved even after OpenCL writes to a partial subset of the pixels.
To reduce the memory footprint for common algorithms you may only need a single texture channel, GL_R for example. This case has been tested with the same sample code and works. The important thing to remember is to make sure the formats match and the height and width match the size of the workgroup expected in the OpenCL kernel. The easiest way to ensure this is to only have a single value for each of the global dimensions (height and width) used for the texture creation in OpenGL as well as the workgroup size when calling clEnqueueNDRangeKernel().
1 size_t global_dim[2];
2 global_dim[0] = CL_GL_SHARED_TEXTURE_HEIGHT;
3 global_dim[1] = CL_GL_SHARED_TEXTURE_WIDTH;
4
5 status = clEnqueueNDRangeKernel(g_clCommandQueue, cl_kernel_drawBox, 2, NULL, global_dim, NULL, 0, NULL, NULL);
3. OpenCL: Using the OpenGL handle created in Step 2, create an OpenCL surface with the call clCreateFromGLTexture().
01 void ShareGLBufferWithCL()
02 {
03 int status = 0;
04 g_SharedRGBAimageCLMemObject = clCreateFromGLTexture( g_clContext,
05 CL_MEM_WRITE_ONLY,
06 GL_TEXTURE_2D,
07 0,
08 g_RGBAbufferGLBindName,
09 &status);
10 if(status == 0)
11 {
12 printf("Successfully shared!\n");
13 }
14 else
15 {
16 printf("Sharing failed\n");
17 }
18 }
This is the key API call for surface sharing between OpenGL and OpenCL. We pass in the previously created OpenCL context, the read and write properties to describe whether we intend to read, write, or both read and write the OpenGL texture, and the name created by the previous OpenGL API call to glGenTextureName(). The output is a cl_mem object that is treated as any regular image in your OpenCL kernel. In fact, if your kernel works on images that were only in an OpenCL path that same kernel will work on textures from OpenGL so long as the parameters are specified that align with the parameters specified when setting up the OpenGL texture!
Writing to the shared surface in OpenCL
1. Mark the surface for OpenCL exclusive access
When OpenCL is writing to the surface, you are required to lock the surface via a Map/Unmap API call to OpenCL. This ensures that OpenGL will not try to change the contents or use the surface in any way while OpenCL is writing to the surface. Also, if the extension cl_khr_gl_event is not supported, prior to acquiring the OpenGL objects we must ensure any OpenGL operations that access the OpenGL objects have completed. The specification is clear that the only portable way to do this without cl_khr_gl_event is to call glFinish() and you must ensure they do not issue any additional commands that affect the GL surface.
However, since Intel processor graphics supports the cl_khr_gl_event you can take advantage of the following:
“In addition, this extension modifies the behavior of clEnqueueAcquireGLObjects and clEnqueueReleaseGLObjects to implicitly guarantee synchronization with an OpenGL context bound in the same thread as the OpenCL context.”
1 status = clEnqueueAcquireGLObjects(
2 g_clCommandQueue,
3 1,
4 &g_SharedRGBAimageCLMemObject,
5 0, 0, 0);
2. Write to the surface via the OpenCL C kernel. In the case of texture data, be sure to use the image read and/or write functions and pass in the image appropriately
The kernel in this example does an update to only a subset of the pixels in the OpenCL C kerneldrawRect(). There are two important aspects. First, the kernel signature:
kernel void drawBox(__write_only image2d_t output)
Note we declared a 2D image that is passed into the kernel with a __write_only attribute.
Next, the write to the output image:
write_imagef(output, coord, color);
This writes to the (u,v) position of image output the value color. Note that writing images does not require samplers but if we were reading from the image we would have the option of including a sampler.
3. Unmark exclusive access to the surface so that OpenGL may now utilize the content.
This is the final interesting API call before rendering, essentially unlocking the surface or releasing it so OpenGL can utilize the updated content. Again, because Intel processor graphics supports the synchronization object extension, you can take advantage of the implicit synchronization guarantee and we do not need to call clFinish() before executing the OpenGL commands on the texture.
1 status = clEnqueueReleaseGLObjects(g_clCommandQueue,
2 1,
3 &g_SharedRGBAimageCLMemObject,
4 0, NULL, NULL);
It is easy to see how these calls fit together in a runtime render loop that is locking, updating, then unlocking the surface each frame:
01 void simulateCL()
02 {
03 cl_int status;
04 static float fDimmerSwitch = 0.0f;
05
06 status = clEnqueueAcquireGLObjects(g_clCommandQueue, 1,
07 &g_SharedRGBAimageCLMemObject, 0, 0, 0);
08
09 status = clSetKernelArg(cl_kernel_drawBox, 0, sizeof(cl_mem),
10 &g_SharedRGBAimageCLMemObject);
11 testStatus(status, "clSetKernelArg");
12
13 size_t global_dim[2];
14 global_dim[0] = CL_GL_SHARED_TEXTURE_HEIGHT;
15 global_dim[1] = CL_GL_SHARED_TEXTURE_WIDTH;
16
17 status = clEnqueueNDRangeKernel(g_clCommandQueue, cl_kernel_drawBox, 2, NULL,
18 global_dim, NULL, 0, NULL, NULL);
19
20 status = clEnqueueReleaseGLObjects(g_clCommandQueue, 1,
21 &g_SharedRGBAimageCLMemObject, 0, NULL, NULL);
22 }
The entire OpenCL C kernel function is trivial and just updates a subset of the image values.
01 kernel void drawBox(__write_only image2d_t output, float fDimmerSwitch)
02 {
03 int x = get_global_id(0);
04 int y = get_global_id(1);
05
06 int xMin = 0, xMax = 1, yMin = 0, yMax = 1;
07
08 if((x >= xMin) && (x <= xMax) && (y >= yMin) && (y <= yMax))
09 {
10 write_imagef(output, (int2)(x, y), (float4)(0.f, 0.f, fDimmerSwitch, 1.f));
11 }
12 }
Shutdown
1. Cleanup the CL memory object
OpenCL objects need to be cleaned up. The only relevant objects here is the cl_mem object associated with the OpenGL texture.
1 //cleanup all CL queues, contexts, programs, mem_objs
2 status = clReleaseMemObject(g_SharedRGBAimageCLMemObject);
2. Cleanup the GL surfaces
glDeleteTextures(1, &g_RGBAbufferGLBindName);
Note Other objects need to be cleaned up for both OpenGL and OpenCL that are shown in the example code.
Would using sync objects and not use implicit synchronization make my code any faster?
At this time Intel processor graphics implements switching between contexts with a flush between OpenCL and OpenGL. Therefore, using explicit synch objects will not result in a performance benefit. Also, programmers are not required to insert their own flush or finish between them when using implicit synchronization.
Additional Details
In the example code the glewExperimental flag must be set to GL_TRUE before callingglewInit() to enable the use of the vertex array objects and used in this example.
Future Work
This tutorial covers the basics of surface sharing. In the future, the scope of the tutorial could be expanded to cover additional use cases touched on here.
Explicit synchronization events between OpenCL and OpenGL
OpenCL has the ability to create an OpenCL event object with GLsync fence objects with the extensioncl_khr_gl_event. Similarly, there is an OpenGL extension to share with OpenCL via theGL_ARB_cl_event extension to share an OpenCL event with OpenGL. While it has been stated that using these provides no performance benefit it would be excellent to show this with real code. Also, more complex use cases may require the use of explicit synchronization and it would be useful to understand what to do in these scenarios if any exist.
Sharing Buffers, Framebuffers, Depth, Stencil, and MSAA surfaces
The OpenCL surface sharing extensions with OpenGL support sharing all the types of surfaces that can be created in OpenGL (buffers, depth, etc.), but there are some limitations on the formats of those surfaces described in the extension specification. This tutorial is focused on sharing a texture that is displayed or used as a texture map in OpenGL; however, sharing other surfaces works similarly. The guidance for sharing OpenGL textures and buffers is similar on Intel processor graphics: in OpenGL do not create vertex or pixel buffer objects when sharing surfaces between the APIs.
Double Buffering
We should explore the tradeoffs in complexity and performance using a double buffering scheme. In this tutorial we focused on functionality and the basics of surface sharing with implicit synchronization.
What to do when no surface sharing is supported?
Maxim Shevtsov has some example code in the References section that covers the case of when a copy must take place between OpenCL and OpenGL, and I recommend you consult his sample code for this use case. Right now, Intel does not support surface sharing on Linux* for example. Customer requests can drive changes to this decision.
Surface Sharing Example
To demonstrate surface sharing we wrote this tutorial. We tested it on Intel processor graphics with OpenCL 2.0 and OpenGL 4.3 drivers. However, the same code with minor porting modifications to the startup code would likely work on many more platforms and devices. The OpenGL programmable vertex and pixel shaders are trivial and should also work on much earlier versions of OpenGL. The OpenCL C kernel is very simple but clearly demonstrates the principles of the article.
Dependencies
To build the tutorial you need to download certain libraries and set up the appropriate paths in your include and library path. URLs for these libraries are included in the references below.
- freeglut.h, freeglut.dll-The location of this dynamically linked library should be added to your path. The path to the freeglut binary on the web is included in the references. After download you can unzip the freeglut.dll located in the freeglut\bin directory.
- glew.h, glew32s.lib-This is from GLEW version 1.11.0 and handles all the OpenGL API and extension management behind the scenes. Note also the #define GLEW_STATIC before including glew.h.
- cl.h, cl_gl.h, openCL.lib-from the Intel® OpenCL™ SDK
- gl.h – is included in Windows Kits 8.0 directory
I used the following settings but yours will be slightly different:
- Copied the freeglut.dll to the debug or release directory of the tutorial at the Solution level (not the Project level). You may have your favorite way of handling .dlls but this works.
- Set the path to the glew32s.lib library to:
- C:\src\glew-1.11.0\lib\Release\Win32
- Add the location of cl.h and cl_gl.h to your include path. For example,
- C:\Program Files (x86)\Intel\OpenCL SDK\3.0\include\CL
- Add the location of the OpenCL library to your library path: For example,
- C:\Program Files (x86)\Intel\OpenCL SDK\3.0\lib\x86
- Add OpenCL.lib to your set of statically linked libraries.
Sample file and directory structure
This section contains details on how this code is partitioned. The emphasis was to create a simple C example and not a product-quality implementation.
The project is contained in a single directory: CL_20_GL_43_surface_sharing. The name indicates it was tested on an OpenCL 2.0 using OpenGL 4.3 solution. It uses nothing specific to OpenCL 2.0; in fact, we do not even enable the OpenCL 2.0 compiler when compiling the OpenCL kernel. In OpenGL, we use very simple programmable vertex and pixel shaders. Using #version we requested at least version 3.3 for the shaders.
The files are organized as follows:
- main.cpp: contains the main entry point of code, calls to initialize OpenCL, OpenGL, and the windowing system. It also contains a keyboard handler to handle the Escape key event.
- The OpenGL and OpenCL specific APIs are located in separate files, OGL.h and OGL.cpp andOCL.h and OCL.cpp respectively, and some of the common flags or variables used are located incommonCLGL.h.
- An OpenCL shader that simply draws a box into the shared image is in the fileOpenCLRGBAFile.cl and the OpenGL shaders are located in triangles.frag andtriangles.vert.
Building and Running the Example
Build this sample code by selecting Build->Build Solution from the main menu. All of the executables should be generated. You can run them in Visual Studio* directly or go to the Debug and/or Release directories that are located in the same location as the CL_20_GL_43_surface_sharing solution file.
To run the sample, press F5 in the Visual Studio IDE. If you want to run from the command line you must copy the shaders from the project directory to the directory of the executable. The three relevant kernel and shader files are OpenCLRGBAFile.cl, triangles.frag, and triangles.vert.
If you want to learn more
Maxim Shevtsov also has a surface sharing tutorial with working sample code that is available here:https://software.intel.com/en-us/articles/opencl-and-opengl-interoperability-tutorial. He spends time discussing the tradeoffs of using PBOs as well as the use of glMapBuffer() and supports this with sample code. He also shows how to handle the case when the extension is not supported such as the Linux OpenCL implementation. The sample code creates the window with traditional win32 APIs and uses a fixed function OpenGL graphics pipeline, writing a single time varying color to the surface. He also makes an effort to run on additional platforms including Intel CPUs and provides some excellent additional references.
In the sample source for this tutorial, we use freeglut, glew, OpenGL 4.3 programmable vertex and pixel shaders, texture mapping a screen-oriented polygonal surface that is rendered to the display. A minor point is that the sample with this article writes to only a portion of the texture in the OpenCL kernel to demonstrate that the resulting pixel color is the combination of all the per-pixel operations of the OpenGL and OpenCL pipeline working in coordination.
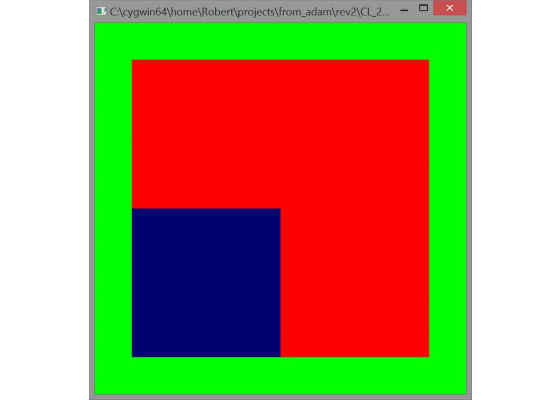
Figure 2. Expected result of sample execution. The green is the background clear color. The image is a screen oriented quadrilateral made of two texture mapped triangles. The texture is a small red 4×4 texture map with the lower left portion of texels being written by OpenCL after being originally populated by OpenGL. OpenCL writes a value to the blue color channel cycling from black to blue (0 to 255 in the blue channel).
Acknowledgements
Thanks to Murali Sundaresan, Aaron Kunze, Allen Hux, Pavan Lanka, Maxim Shevtsov, Michal Mrozek, Piotr Uminski, Stephen Junkins, Dan Petre, and Ben Ashbaugh. All were available for technical discussions, clarifications or reviews along the way.
For more such intel resources and tools from Intel on Game, please visit the Intel® Game Developer Zone
Source: https://software.intel.com/en-us/articles/sharing-surfaces-between-opencl-and-opengl-43-on-intel-processor-graphics-using-implicit/



