")
Introduction
Transportation networks have always been used with the goal of making it easy to move goods from one location to another using the most effective means available. During the last few decades, the definition of “means” has changed to not only include the cost in terms of money but also other factors like environmental impact, energy costs, and time. With the globalization of business and supply chains, the size and complexity of such transportation networks has increased considerably. As a result the problem of optimizing transportation networks is now categorized as an NP-hard problem for which a deterministic solution is often not applicable.
With the rise of multi-core and distributed architectures, optimization techniques based on heuristics including ant colony optimization (ACO) are being developed and applied. In this paper, we baseline and analyze the bottlenecks of one such implementation of ACO and introduce additional improvements we deployed, achieving near theoretical scaling on a four-socket Intel® Xeon® processor-based system. The paper is structured as follows:
- Background of an ACO algorithm
- Baseline implementation with benchmark results and VTune™ Amplifier analysis
- Optimization 1: Using Hybrid MPI-OpenMP* with VTune Amplifier
- Optimization 2: Using Intel® Threading Building Blocks (Intel® TBB) – Dynamic Memory Allocation
- Optimization 3: Combining/Balancing MPI Ranks and OpenMP Threads
- Summary
Background: The ACO Algorithm
When ants search for food, they deposit pheromones along their paths, which attract more ants. But these pheromones evaporate, which degrades longer paths more easily than shorter and/or faster paths meaning more ants are attracted to the shorter, faster paths where they deposit more pheromones and increase the attractiveness of the path.
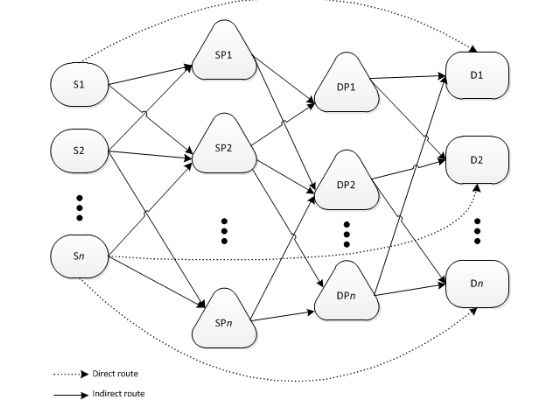
Figure 1: Example of Transportation Network.1
Simple computer agents within a network can probabilistically build solutions using the ACO principle. In the past we have seen the following parallel software implementations for the ACO algorithm but with some limitations.
- M. Randall et al. (Randall & Lewis, 2002) developed a simple parallel version of the ACO algorithm that showed acceptable speedup, but it incurred a large amount of communication to maintain the pheromone matrix. When they used fine-grained parallelism across multiple ants, performance was limited by the Message Passing Interface (MPI) communication between ants.
- Veluscek, M. et al. (Veluscek, 2015) implemented composite goal methods for their transportation network optimization algorithm using an OpenMP-based shared memory parallelism, but it is best run on systems with relatively few cores using a low number of threads.
Baseline Implementation of ACO
The overall parallel architecture of our baseline ACO software is represented using the flowchart shown in Figure 2.
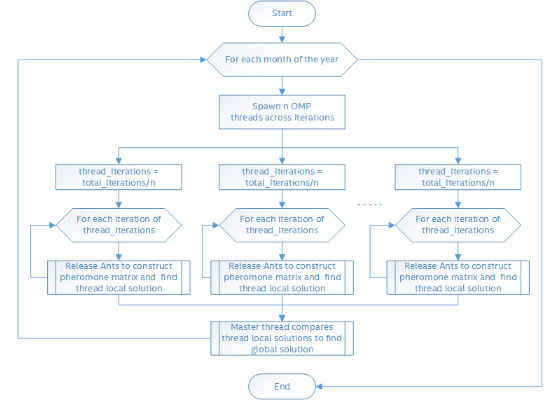
Figure 2: Non-optimized baseline flowchart.
For every month of the year, a large number of iterations are run in which an ant population is released to construct the pheromone matrix contributing to a solution. Each iteration is run entirely independent of the others.
A static distribution of work was used where each OpenMP thread ran its portion of iterations in parallel and found a thread-local solution. Once all the threads completed their search, a master thread compared all the thread-local solutions and picked a global solution.
Benchmark Results – Baseline Implementation
One of the quickest ways to find out whether an application is scaling efficiently with an increasing number of cores is to baseline it using a one-socket/NUMA node and then compare that to the performance when run on multiple sockets with and without hyper-threading. In an ideal scenario, two-socket systems would show double and four-socket systems would show quadruple the single-socket performance (ruling out the effects from other limitations). However, as shown in Figure 3, in our baseline tests, the application did not scale well beyond two sockets (48 cores), let alone 192 cores.
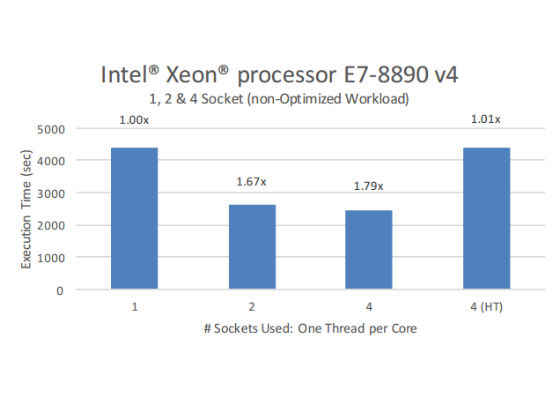
Figure 3: Pre-optimized baseline scaling results.
VTune Amplifier XE Analysis – Baseline Implementation
To find the scaling issue, we used the hotspots feature of VTune Amplifier XE 2016.[1] In Figure 4, the VTune Amplifier summary window shows Top Hotspots and Serial Time spent spinning on serial execution of the network optimization application.
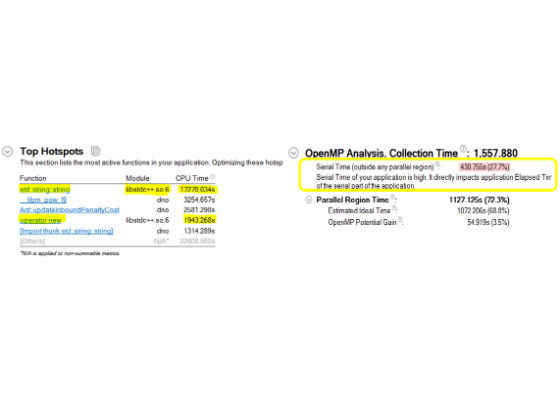
Figure 4: Pre-optimized baseline – Top Hotspots.
From Figure 4, it can be inferred that the application spends a large amount of time executing serially, which directly impacts the parallel CPU usage. The biggest hotspot is the string allocator from the standard string library, which did not scale well to high core counts. This makes sense since OpenMP uses a single shared pool of memory, and a huge number of thread parallel calls to string constructor or object allocator (usingoperatornew) tends to create a memory bottleneck. And if we look at CPU Usage in the bottom-up tab (Figure 5), we find that the application uses all 96 cores, but only for short spurts.
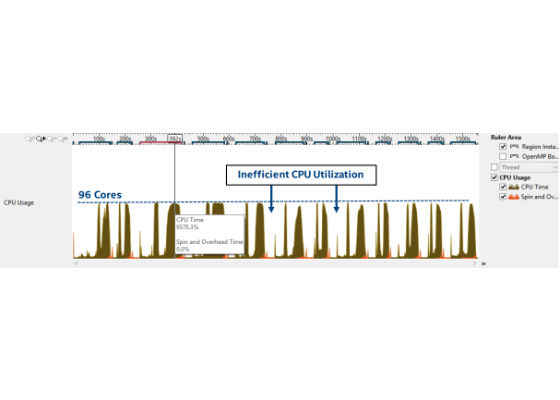
Figure 5: Pre-optimized baseline – CPU utilization.
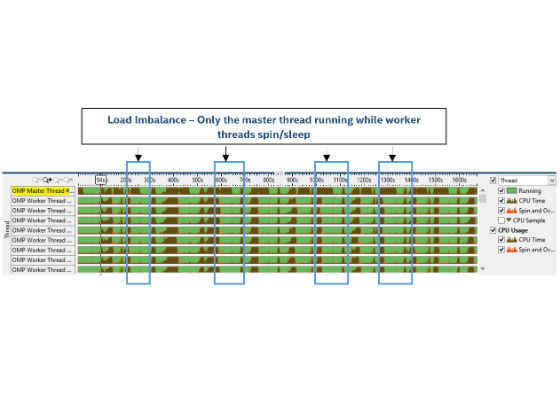
Figure 6: Pre-optimized baseline – Load imbalance.
And when mapping the algorithm to the time line, the load imbalance chart (Figure 6), shows that at the end of every month, there is a small time frame where the master thread is doing useful computations but the rest of the threads end up spinning or sleeping.
Optimization 1: Adding Hybrid MPI-OpenMP
To avoid the large pool of OpenMP threads found in the baseline implementation, we used a generic master-slave approach and launched multiple processes[2] across iterations. For each process (MPI rank) a relatively small number of OpenMP threads were spawned. The overload of string and object allocation is now distributed among multiple MPI processes (ranks). This hybrid MPI-OpenMP implementation of the ACO software is represented by the flowchart shown in Figure 7.
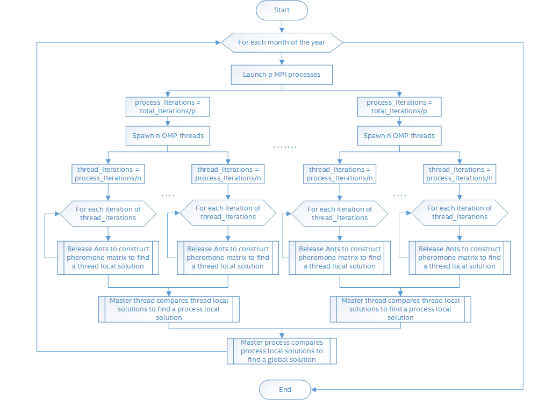
Figure 7: Optimized implementation #1 – flowchart.
VTune Amplifier XE Analysis of Optimization 1
Using the VTune Amplifier hotspot feature, we analyzed the hybrid MPI-OpenMP implementation.
In the summary window (Figure 8) we can see that the application now spends comparatively less time in string allocations with improved CPU utilization (Figure 9a and 9b).

Figure 8: Optimization 1 implementation – Top Hotspots
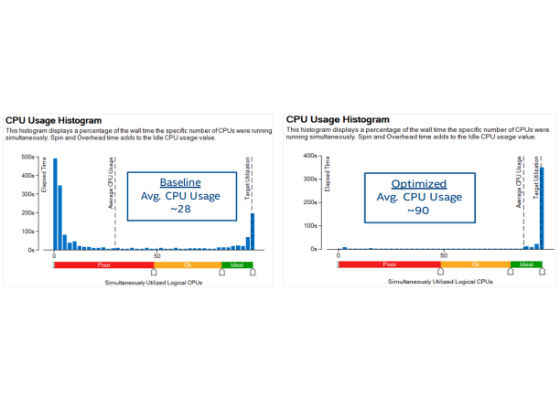
Figure 9: Pre-optimized baseline and optimization # 1 implementation – CPU usage histogram

Figure 10: Optimization #1implementation – elapsed time line.
Figure 10 shows that the resulting load imbalance between the master and worker threads has decreased significantly. Figure 11 shows that the CPU usage is close to 96 cores throughout the time line.
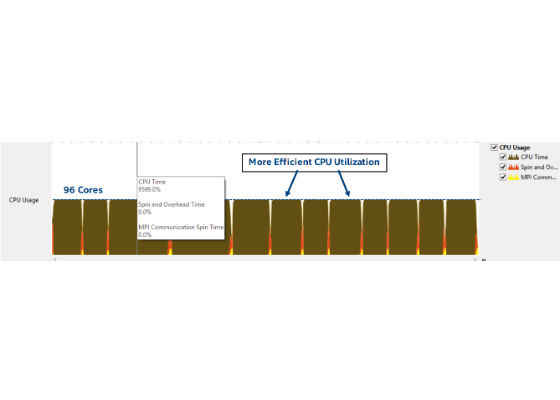
Figure 11: Optimization #1 implementation – CPU utilization.
Unfortunately, we still see too much time spent in the spinning of OpenMP threads and MPI communication when the winner rank (the rank that finds the global solution) sent its solution to the master rank to update the result files. We theorized that this was due to the overhead of MPI communication. The MPI uses a distributed memory interface wherein each process (rank) works on a separate pool of memory. As a result, modification of objects and data structures by one rank is not transparent to the other ranks and so data must be shared between ranks using MPI Send and Receive, including the monthly global solution, which must be sent to the master.[3] This global solution is a complex C++ object, which consists of a number of derived class objects, some smart pointers with data, and other STL template objects. Since by default MPI communication does not support exchanging complex C++ objects, MPI Send and Receive requires serialization to convert the C++ object into a stream of bytes before sending and then deserialization to convert the stream back into objects upon receiving. Figure 11 shows this overhead in yellow (MPI communication) and red (Spin and Overhead).
Results of Optimization 1
The hybrid MPI-OpenMP version showed better load-balancing characteristics between the MPI ranks and OpenMP threads and much more efficient CPU utilization for high core count Intel® Xeon® processor E7-8890 v4 systems. Figure 12 shows it significantly improved scaling over multiple sockets (cores), including with hyper-threading.
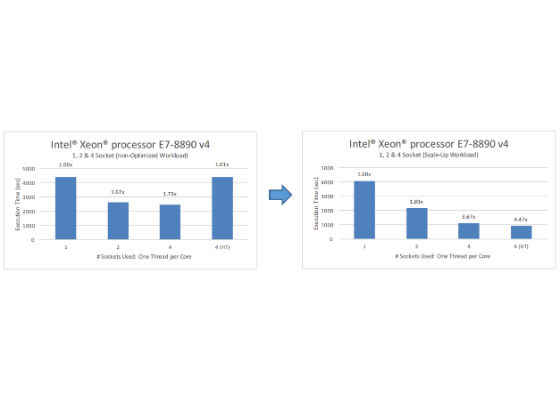
Figure 12: Optimization 2 – scaling comparison.
Optimization 2: Using Intel® Threading Building Blocks Dynamic Memory Allocation
Looking at the top hotspots for the hybrid MPI-OpenMP runs, we saw that a significant portion of execution time was used by the standard string allocation library. We thought it would be interesting to see if the dynamic memory allocation library from Intel TBB would be beneficial. Intel TBB provides several memory allocator templates that are similar to the standard template library (STL) template class std::allocator, including scalable_allocator<T> and cache_aligned_allocator<T>. These address two critical issues in parallel programming:
Scalability issues, which occur because memory allocators sometimes have to compete for a single shared pool in a way that allows only one thread to allocate at a time (due to the original serial program design).
False sharing problems, which arise when two threads access different words in the same cache line. Because the smallest unit of information exchanged between processor caches is a cache line, a line will be moved between processors, even if each processor is dealing with a different word within that line. False sharing can hurt performance because cache lines moves can take hundreds of clocks.
Steps to use Intel Threading Building Blocks Dynamic Memory Allocation
One of the easiest ways to find out whether the application can benefit from Intel TBB dynamic memory allocation is to replace the standard dynamic memory allocation functions with the release version of the Intel TBB proxy library – libtbbmalloc_proxy.so.2. Simply load the proxy library at program load time using the LD_PRELOAD environment variable (without changing the executable file), or link the main executable file with the proxy library.
Link with the TBB malloc proxy library: -ltbbmalloc_proxy
OR
Set LD_PRELOAD environment variable to load the Intel® TBB malloc proxy library
$ export LD_PRELOAD=libtbbmalloc_proxy.so.2
Results of Optimization 2
Addressing the critical issue of scalability of default memory allocators, the Intel TBB dynamic memory allocation proxy library provides an additional 6 percent gain over the optimized scale-up hybrid MPI-OpenMP version (Figure 13).

Figure 13: Scale-up implementation – Intel® Threading Building Blocks improvements.
Optimization 3: Combining MPI Ranks and OpenMP Threads
Finally, further tuning was run which experimented with different combinations of MPI ranks and OpenMP threads running the same workload. With hyperthreading turned ON, we ran the workload while maximizing the total system usage, that is, using all of the 192 logical cores. Figure 14 shows the maximum throughput achieved when we ran a combination of 64 MPI ranks each running 3 OpenMP threads.
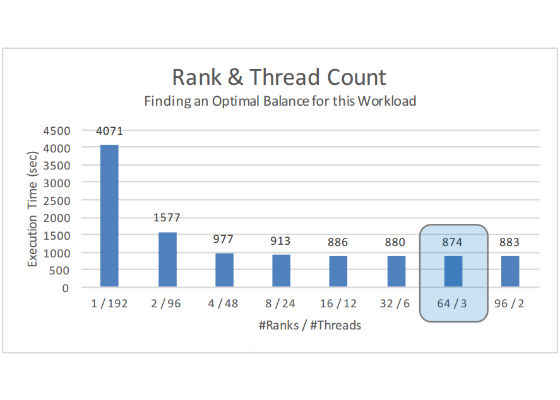
Figure 14: Optimization 3– comparison of rank and thread count combinations.
For more such intel Machine Learning and tools from Intel, please visit the Intel® Machine Learning Code
Source: https://software.intel.com/en-us/articles/scale-up-implementation-of-a-transportation-network-using-ant-colony-optimization-aco



