
Purpose
This recipe describes a step-by-step process of how to get, build, and run NAMD, Scalable Molecular Dynamic, code on Intel® Xeon Phi™ processor and Intel® Xeon® E5 processors for better performance.
Introduction
NAMD is a parallel molecular dynamics code designed for high-performance simulation of large biomolecule systems. Based on Charm++ parallel objects, NAMD scales to hundreds of cores for typical simulations and beyond 500,000 cores for the largest simulations. NAMD uses the popular molecular graphics program VMD for simulation setup and trajectory analysis, but is also file-compatible with AMBER, CHARMM, and X-PLOR.
NAMD is distributed free of charge with source code. You can build NAMD yourself or download binaries for a wide variety of platforms. Find the details below of how to build on Intel® Xeon Phi™ processor and Intel® Xeon® E5 processors and learn more about NAMD at http://www.ks.uiuc.edu/Research/namd/
Building and running NAMD on Intel® Xeon® Processor E5-2697 v4 (BDW) and Intel® Xeon Phi™ Processor 7250 (KNL)
Download the Code:
1. Download the latest “Source Code” of NAMD from this site:http://www.ks.uiuc.edu/Development/Download/download.cgi?PackageName=NAMD
2. Download charm++ 6.7.1 version
- You can get charm++ from the NAMD “Source Code” of the “Version Nightly Build”
- Or download it separately from here http://charmplusplus.org/download/
3. Download fftw3 version(http://www.fftw.org/download.html)
- Version 3.3.4 is used is this run
4. Download apao1 and stvm workloads from here: http://www.ks.uiuc.edu/Research/namd/utilities/
5. Download stmv.28M for large scale runs from http://www.prace-ri.eu/ueabs/#NAMD(TestCaseB)
Build the Binaries:
1. Recommended steps to build fftw3:
- Cd<path>/fftw3.3.4
- ./configure –prefix=$base/fftw3 –enable-single –disable-fortran CC=icc
Use xMIC-AVX512 for KNL or –xCORE-AVX2 for BDW
- make CFLAGS="-O3 -xMIC-AVX512 -fp-model fast=2 -no-prec-div -qoverride-limits" clean install
2. Build multicore version of charm++:
- cd <path>/charm-6.7.1
- ./build charm++ multicore-linux64 iccstatic –with-production "-O3 -ip"
3. Build BDW:
- Modify the Linux-x86_64-icc.arch to look like the following:
NAMD_ARCH = Linux-KNL
CHARMARCH = multicore-linux64-iccstatic
FLOATOPTS = -ip -xMIC-AVX512 -O3 -g -fp-model fast=2 -no-prec-div -qoverride-limits -DNAMD_DISABLE_SSE
CXX = icpc -std=c++11 -DNAMD_KNL
CXXOPTS = -static-intel -O2 $(FLOATOPTS)
CXXNOALIASOPTS = -O3 -fno-alias $(FLOATOPTS) -qopt-report-phase=loop,vec -qopt-report=4
CXXCOLVAROPTS = -O2 -ip
CC = icc
COPTS = -static-intel -O2 $(FLOATOPTS)
- ./config Linux-x86_64-icc –charm-base <charm_path> –charm-arch multicore-linux64- iccstatic –with-fftw3 –fftw-prefix <fftw_path> –without-tcl –charm-opts –verbose
- gmake -j
4. Build KNL:
- Modify the arch/Linux-KNL-icc.arch to look like the following:
NAMD_ARCH = Linux-KNL
CHARMARCH = multicore-linux64-iccstatic
FLOATOPTS = -ip -xMIC-AVX512 -O3 -g -fp-model fast=2 -no-prec-div -qoverride-limits -DNAMD_DISABLE_SSE
CXX = icpc -std=c++11 -DNAMD_KNL
CXXOPTS = -static-intel -O2 $(FLOATOPTS)
CXXNOALIASOPTS = -O3 -fno-alias $(FLOATOPTS) -qopt-report-phase=loop,vec -qopt-report=4
CXXCOLVAROPTS = -O2 -ip
CC = icc
COPTS = -static-intel -O2 $(FLOATOPTS)
- ./config Linux-KNL-icc –charm-base <charm_path> –charm-arch multicore-linux64-iccstatic –with-fftw3 –fftw-prefix <fftw_path> –without-tcl –charm-opts –verbose
- gmake –j
Other system setup:
1. Change the kernel setting for KNL: “nmi_watchdog=0 rcu_nocbs=2-271 nohz_full=2-271”One of the ways to change the settings (this could be different for every system):
- First save your original grub.cfg to be safe
cp /boot/grub2/grub.cfg /boot/grub2/grub.cfg.ORIG
- In “/etc/default/grub”. Add (append) the below to the “GRUB_CMDLINE_LINUX”
nmi_watchdog=0 rcu_nocbs=2-271 nohz_full=2-271
- Save your new configuration
grub2-mkconfig -o /boot/grub2/grub.cfg
- Reboot the system. After logging in, verify the settings with 'cat /proc/cmdline’
2. Change next lines in *.namd file for both workloads:
numsteps 1000
outputtiming 20
outputenergies 600
Run NAMD:
1. Run BDW (ppn = 72):
$BIN +p $ppn apoa1/apoa1.namd +pemap 0-($ppn-1)
2. Run KNL (ppn = 136, MCDRAM in flat mode, similar performance in cache):
numactl –m 1 $BIN +p $ppn apoa1/apoa1.namd +pemap 0-($ppn-1)
Example: numactl –m 1 /NAMD_2.11_Source/Linux-KNL-icc/namd2 +p 136 apoa1/apoa1.namd +pemap 0-135
Performance results reported in Intel Salesforce repository (ns/day; higher is better):

Systems configuration:
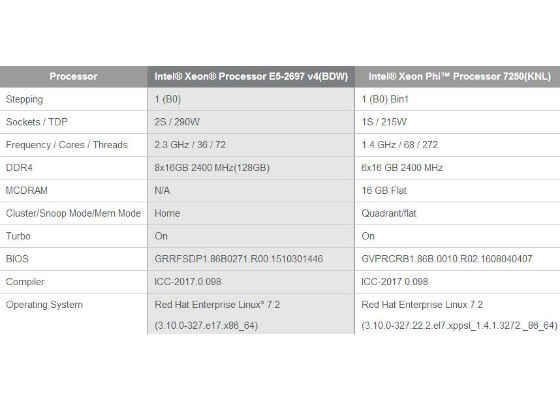
Building and running NAMD for Cluster on Intel® Xeon® Processor E5-2697 v4 (BDW) and Intel® Xeon Phi™ Processor 7250 (KNL)
Build the Binaries:
1. Set Intel tools for compilation:
I_MPI_CC=icc;I_MPI_CXX=icpc;I_MPI_F90=ifort;I_MPI_F77=ifort
export I_MPI_CC I_MPI_CXX I_MPI_F90 I_MPI_F77
CC=icc;CXX=icpc;F90=ifort;F77=ifort
export CC CXX F90 F77
export I_MPI_LINK=opt_mt
2. Recommended steps to build fftw3:
- Cd<path>/fftw3.3.4
- ./configure –prefix=$base/fftw3 –enable-single –disable-fortran CC=icc
- Use xMIC-AVX512 for KNL or –xCORE-AVX2 for BDW
- make CFLAGS="-O3 -xMIC-AVX512 -fp-model fast=2 -no-prec-div -qoverride-limits" clean install
3. Recommended steps to build multicore version of charm++:
- cd <path>/charm-6.7.1
- chmod –R 777 *
- source /opt/intel/compiler/<version>/compilervars.sh intel64
- source /opt/intel/impi/<version>/bin/mpivars.sh
- ./build charm++ mpi-linux-x86_64 smp mpicxx ifort –with-production $base_charm_opts -DCMK_OPTIMIZE -DMPICH_IGNORE_CXX_SEEK
4. Build on KNL:
- ./config Linux-KNL-icc –charm-base < fullPath >/charm-6.7.1 –charm-arch mpi-linux-x86_64-ifort-smp-mpicxx –with-fftw3 –fftw-prefix <fullPath>/fftw3 –without-tcl –charm-opts –verbose
- cd “Linux-KNL-icc”
- gmake -j
5. Build on BDW:
- ./config Linux-KNL-icc –charm-base $FULLPATH/charm-6.7.1 –charm-arch mpi-linux-x86_64-ifort-smp-mpicxx –with-fftw3 –fftw-prefix $FULLPATH/fftw3 –without-tcl –charm-opts -verbose
- cd Linux-KNL-icc
- make clean
- gmake –j
6. Build memopt NAMD binaries:
- Like BDW/KNL build with extra options “–with-memopt” for config.
Run the Binaries (ps: “hosts”: is the file that contains the host names to run on):
1. BDW run on single node:
export I_MPI_PROVIDER=psm2
export I_MPI_FALLBACK=no
export I_MPI_FABRICS=tmi
source /opt/intel/compiler/<version>/compilervars.sh intel64
source /opt/intel/impi/<version>/intel64/bin/mpivars.sh
NTASKS_PER_NODE=1
export MPPEXEC="time -p mpiexec.hydra -perhost $NTASKS_PER_NODE -f ./hosts "
$MPPEXEC -n $node $BINPATH/$BINNAME +ppn 71 $FULLPATH/$WORKLOAD +pemap 1-71 +commap 0
Example:
$MPPEXEC -n 1 $FULLPATH/namd2” +ppn 71 $FULLPATH/stmv/stmv.namd” +pemap 1-71 +commap 0
2. KNL Run on single node:
export I_MPI_PROVIDER=psm2
export I_MPI_FALLBACK=0
export I_MPI_FABRICS=tmi
export PSM2_IDENTIFY=1
export PSM2_RCVTHREAD=0
export TMI_PSM2_TEST_POLL=1
NTASKS_PER_NODE=1
export MPPEXEC="mpiexec.hydra -perhost $NTASKS_PER_NODE -f ./hosts "
numactl -m 1 $MPPEXEC $BINPATH/$BINNAME +ppn 135 $FULLPATH/$WORKLOAD +pemap 1-135 +commap 0
Example:
numactl -m 1 $MPPEXEC $FULLPATH/namd2 +ppn 135 $FULLPATH/stmv/stmv.namd +pemap 1-135 +commap 0
3. KNL Run on multi-node (node = number of nodes to run on):
export MPPEXEC="mpiexec.hydra -perhost 1 -f ./hosts "
numactl -m 1 $MPPEXEC -n $node numactl -m 1 $BINPATH/$BINNAME +ppn 134 $FULLPATH/$WORKLOAD +pemap 0-($ppn-1) +commap 67
Example:
numactl -m 1 $MPPEXEC -n 8 numactl -m 1 $FULLPATH/namd2 +ppn 134 $FULLPATH/stmv/stmv.nand +pemap 0-66+68 +commap 67
Remark:
For better scale on multinodes run, please increase count of communication threads (1, 2, 4, 8, 13, 17). Example of a command run that can be used:
export MPPEXEC="mpiexec.hydra -perhost 17 -f ./hosts "
numactl -m 1 $MPPEXEC -n $(($node*17)) numactl -m 1 $BINPATH/$BINNAME +ppn 7 $FULLPATH/$WORKLOAD +pemap 0-67,68-135:4.3 +commap 71-135:4 > ${WKL}_cluster_commapN/${WKL}.$node.$
One usage example:
nodes="16 8 4 2 1"
for node in ${nodes}
do
export MPPEXEC="mpiexec.hydra -perhost 17 -f ./hosts
numactl -m 1 $MPPEXEC -n $(($node*17)) numactl -m 1 $FullPath.namd2 +ppn 8 $WorkloadPath/$WKL/$WKL.namd +pemap 0-67+68 +commap 71-135:4 > $ResultFile.$node.$BINNAME.68c2t.commap_8th_from2cx4t
done
Best performance results reported on up to 128 Intel Xeon Phi nodes cluster (ns/day; higher is better):
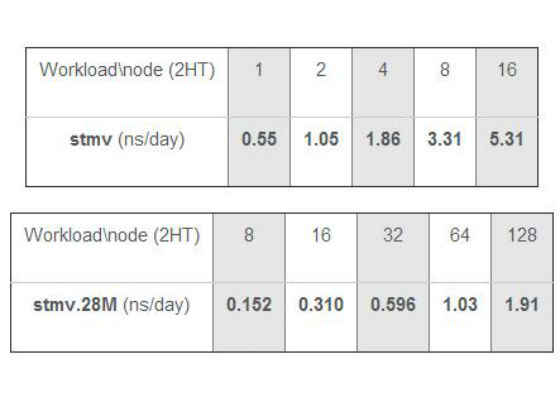
For more such intel Modern Code and tools from Intel, please visit the Intel® Modern Code
Source:https://software.intel.com/en-us/articles/building-namd-on-intel-xeon-and-intel-xeon-phi-processor



