
Over time, Intel and other processor vendors add more and more instructions to the processors that power our phones, tablets, laptops, workstations, servers, and other computing devices. Adding instructions for particular compute tasks is a good way to gain processing efficiency without the need to make processor pipelines more complex or drive clock frequencies into unattainable territories. If a new instruction can replace a few old ones, you can easily get many times better performance on particular tasks. New instructions also provide entirely new functionality – for example, Intel® Software Guard Extensions (SGX) and Intel® Control-Flow Enforcement (CET).
A good question is how quickly and easily new instructions added to the Instruction-Set Architecture (ISA) reach users. Considering that our operating systems and programs are generally backwards-compatible, and run on all kind of hardware, can they actually take advantage of new instructions? In the old days, you did this by recompiling your software for a new architecture and adding checks to avoid running on an old machine where the software would break (“sorry, this program is not supported on this hardware”).
I played around with my favorite virtual platform tool, Wind River® Simics®, to find out to what extent software today is capable of making use of newer instructions, while remaining compatible with older hardware.
The Experimental Setup
To investigate whether software can adapt dynamically to newer hardware, I took our “generic PC” platform in Simics and ran it with two different processor models. One model was of an Intel® Core™ i7 first-generation processor (codename “Nehalem”), and the other model was of an Intel Core i7 sixth-generation processor (codename “Skylake”).
The first-gen processor was launched in late 2008 – I actually got myself a PC with an Intel Core i7-970 processor back in early 2009—a wonderful machine fitted with three memory channels so I could cram 9GB of RAM in it. The sixth-gen processor was launched in mid-2015, roughly seven years later.
I booted three different Linux* operating system (OS) setups on both hardware configurations:
- Ubuntu* 16.04 with kernel 4.4, released in early 2016
- Yocto* 1.8 with kernel 3.14, released in early 2014
- Busybox* with kernel 2.6.39, released in 2011
The same disk image was used on old and new hardware – nothing was changed in the software stack between the runs. Only the virtual hardware configuration differed. I expected the newer Linux operating systems would make use of newer instructions on the newer hardware. Spoiler: they did, but sometimes in surprising ways.
On each setup, Simics instrumentation counted the dynamic frequency of instructions (executed instruction count), grouped by opcode (assembly instruction name as used by Simics processors). The Simics instrumentation is non-intrusive and does not introduce any changes to the execution of the target system. Since it operates at the hardware level, we can instrument right through the BIOS and OS kernel boot. The software running on the target system cannot tell the difference between instrumented and non-instrumented execution.
Each setup was run for 60 virtual seconds, which was enough to get through BIOS and OS boot, and to a desktop or user prompt in all cases. At the end of each run, the 100 most common instructions were listed along with their frequency, and the data was exported to Excel for further processing and analysis.
Investigating the Nature of the Hardware
The underlying assumption of this work is that software stacks can dynamically adapt the code that runs, based on the nature of the hardware. Thus, a single binary setup will potentially use different instructions on different hardware platforms.
The key to such dynamic adaptation is to detect the nature of the hardware that the software is running on. Back when processor releases were few and far between, software might check if you had an Intel 80386 or 80486 processor, or a Motorola* 68020 or 68030 and adapt accordingly. Processors came out every few years, and the variety was limited. Today, there is more diversity, especially considering the huge installed base of a large variety of systems. To deal with this, IA processors have the CPUID instruction. CPUID is a system in its own right, where numerous aspects of the hardware can be queried.
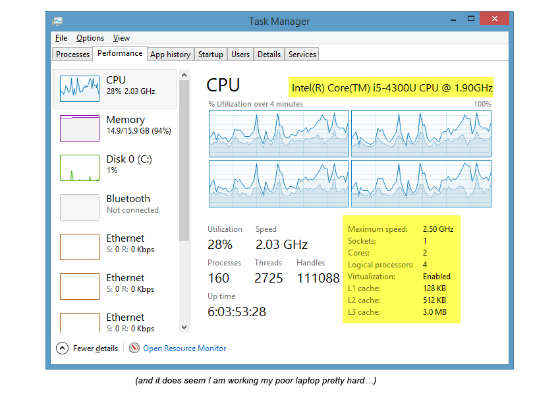
You have probably seen information from the CPUID instruction without thinking about the source; every time a program tells you the type of your processor, it is based on CPUID output. For example, the Microsoft* Windows* 8.1 task manager shows the processor type and some of its characteristics – all of which it gets from CPUID:
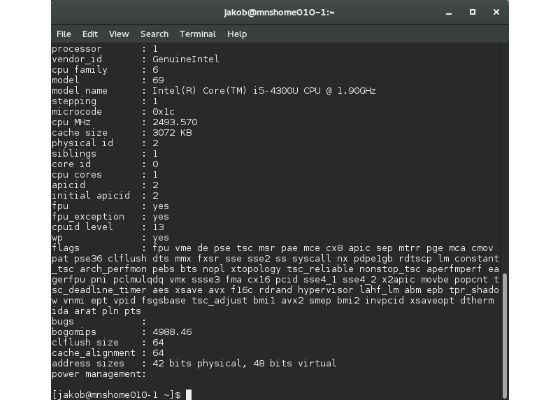
On Linux, doing “cat /proc/cpuinfo” will show CPUID information for a much rawer insight into the processor, including flags showing the available processor features and instruction sets. Each instruction set addition gets its own flag or flags that software can use to determine the availability of features. For example, here is what you see with a 4th generation Core i5 processor:
CPUID will tell the software about the various instruction set extensions and hardware features available, but how does software actually use the flags to choose different code depending on the host? It seems unreasonable to pepper code with conditionals like “if instruction set X is available, then do this…” The code has to avoid checking the same information over and over again, since it is not going to change during a run.
In the Linux kernel, the most common way to do this is to set up function pointers for different implementations of the same function, based on the available instruction sets. A good example is found in arch/x86/crypto/sha1_ssse3_glue.c in the Linux kernel 4.13.5 (as indexed by http://elixir.free-electrons.com/linux/v4.13.5/source):

These functions check if the boot processor supports a particular instruction set, and they register the appropriate hashing functions accordingly. They are called in order of priority, to make sure the most efficient solution is used. The best solution for this particular case is apparently to have a processor thatsupports specialized SHA instructions, but if that is not available, the kernel falls back to AVX or SSE.
With that in mind, it is time to run the code and see which instructions get used.
Results
The graph below summarizes the results from six different runs (two types of processor cores each with three different operating system variants). It shows all instructions that occur more than 1% in any of the runs. “v1” means the software stack was run on a 1st generation Core i7, and “v6” means it was run on a 6th generation Core i7.
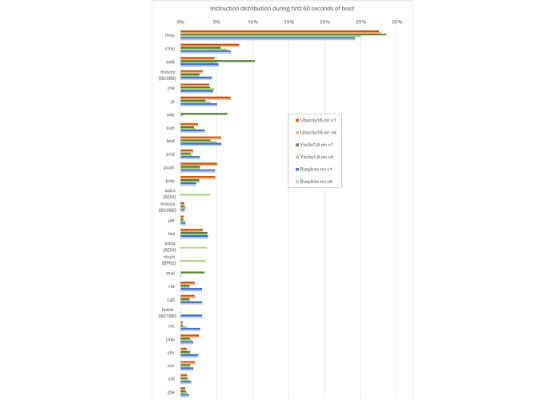
The first conclusion is that most instructions are not particularly new, but rather the basics harkening back to the Intel 8086: moves, compares, jumps, and adds. Newer instructions are marked with the instruction set extension that they belong to, and there are only six of them in the top 28 instructions shown in the graph.
It is clear that there is a lot variety between the software stacks, in addition to variation across processor generations. For example, the old Busybox setup uses the LEAVE instruction, which the others generally do not, and it uses far fewer POPs. However, that does not address whether software stacks take advantage of new instructions when they are available. The most interesting variation is between processor generations for the same software stack.
Different runs could do different things. In this case, even though all runs are Linux boots, there are variations in the kernel configuration and the contents of the root file system. Different distributions and kernel versions will be built with different compiler versions and different compiler settings. Thus, the executable code generation for the same source code might be different. There are many ways to generate machine code to achieve the same effects, and the way that is done changes over time, and it changes with different target machine optimization settings in the compiler.
We do see some of that in the data: the Yocto setup is unique in using the ADCX, MULX, and ADOX instructions (from the ADX and BMI2 sets of instructions). This also shows the speed at which new instructions can get into software – these instructions were added in the fifth generation of Intel Core processors, which were released about the same time as that Linux kernel. When the processors came on the market, the software support was already there. Indeed, specs for new instructions usually come out well in advance of the hardware implementation (see an overview in this paper), and thus software support can be added early (quite often tested on virtual platforms modeling future hardware variants, so when the hardware comes out, it just works).
However, the newer Ubuntu 16.04 setup does not use the ADX and BMI2 instructions, which indicates that it was built in a different way. It could be the compiler version used, compiler flags, or kernel flags, or the particular packages present on the disk image.
Control Transfers
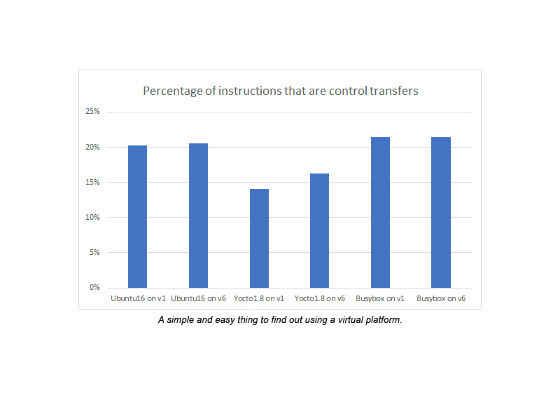
Another thing I checked was how common control transfer instructions were. The classic rule-of-thumb from Hennessy and Patterson was that one instruction in six was a jump. However, it seems more common in the Linux code base I tried here—about one instruction in five was a control transfer of some kind. But for the Yocto stacks, it was more like one in six. Once again, there was more variation than one might expect.
Vector Instructions
When talking about new instruction sets, the most well-known category is probably single-instruction multiple-data (SIMD) or vector instructions. SIMD instructions have been around since Intel released the MMX instruction set with the Intel Pentium® Processor with MMX in 1997. Today, their presence is taken for granted. An MMX instruction almost made it into the “most popular” instructions graph presented above – just below the threshold there was the PXOR instruction. After MMX came Intel® Streaming SIMD Extensions (SSE) in various generations, and most recently Intel® Advanced Vector Extensions (AVX), AVX2, and AVX512.
Since I did my investigation on operating system boots, I would not expect much usage of vector instructions. However, some five to six percent of the executed instructions were vector instructions. I took a look at which instruction set extensions they belonged to. Grouping the instructions by the particular instruction set variant, I got the following data:
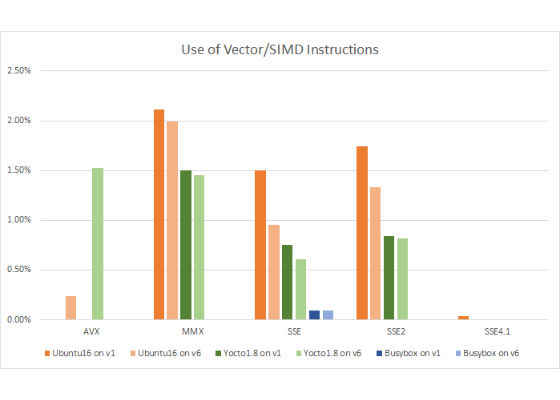
The first thing to note is that the Busybox build hardly uses vector instructions. The next thing to note is that as we go from v1 to v6 processors, the use of older instruction sets go down, and the use of newer ones go up. In particular, there is a move toward AVX from the older SSE instruction sets. The 6th generation core i7 supports AVX2, but it is not being used by these software stacks at all.
Simics Technology
As stated earlier, doing this in the Simics virtual platform was easy. Simics trivially accesses all instructions executed, across all processors in the target system (I used dual-core setups for the experiment, but it turned out the second core did nothing during the boot and at OS idle). The boots were all fully automated, including selecting boot devices and logging into the target system at the end of the boot, so there was no manual intervention.
I ran each test only once, as running it again would give the exact same results (since we are looking at a repeatable scenario, starting from the same point each time). Everything is repeatable unless intentionally changed, including aspects like the real-time clock setting for the target system (it is a parameter to the simulation and not taken from the outside world).
Summary
It was enlightening to see how software stacks adapt to use newer instructions in newer processors. Today, we have software that is adaptive and will behave differently depending on the hardware it is running on—without changing any binaries—the adaptiveness is built right in. In all the cases I tried here, I used the same software stack for two different types of target systems, and saw them use different instructions depending on what was available on each target system (except for the case when the software stack was so old that it did not know about the features of the newer hardware). The study is an example of the kind of data collection that is easy to do in a simulator, but tricky to carry out in hardware.
For more such intel IoT resources and tools from Intel, please visit the Intel® Developer Zone
Source:https://software.intel.com/en-us/blogs/2017/10/17/does-software-actually-use-new-instruction-sets



