
Background on AI and the Move to the Edge
Our daily lives intersect with artificial intelligence (AI)-based algorithms. With fits and starts, AI has been a domain of research over the last 60 years. Machine learning, or the many layers of deep learning, are propelling AI into all parts of modern life. Its applied usages are varied, from computer vision for identification and classification to natural language processing, to forecasting. These base-level tasks then lead to higher level tasks such as decision making.
What we call deep learning is typically associated with servers, the cloud, or high-performance computing. While AI usage in the cloud continues to grow, there is a trend toward AI inference engine on the edge (i.e. PCs, IoT devices, etc.). Having devices perform machine learning locally versus relying solely on the cloud is a trend driven by the need to lower latency, to ensure persistent availability, to reduce costs (for example, the cost of running inferencing algorithms on servers), and to address privacy concerns. Figure 1 shows the phases of deep learning.
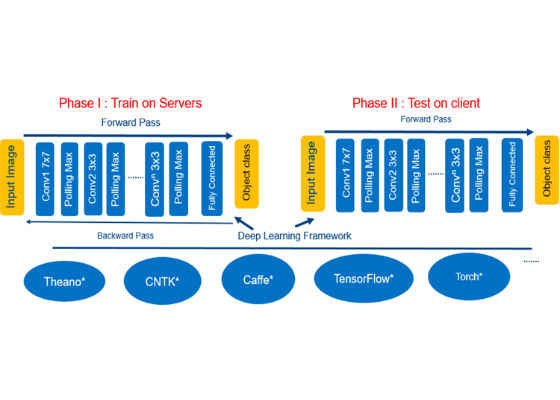
Figure 1. Deep learning phases
Moving AI to consumers – Personify* is an expert system performing real-time image segmentation. Personify enabled real-time segmentation within the Intel® RealSense™ camera in 2015. In 2016, Personify launched ChromaCam*, an application that can remove/replace/blur the user's background in all major video chat apps like Microsoft Skype*, Cisco WebEx*, and Zoom* as well as streaming apps like OBS and XSplit*. ChromaCam uses deep learning to do dynamic background replacement in real-time and works with any standard 2D webcam commonly found on laptops.

Figure 2. Personify segmentation
One of the requirements for Personify is to run an inference engine process on their deep learning algorithm on the edge as fast as possible. To get good segmentation quality, Personify needs to run the inference algorithm on the edge to avoid the unacceptable latencies of the cloud. The Personify software stack runs on CPUs and graphics processing units (GPUs), and was originally optimized for discrete graphics. However, running an optimized deep learning inference engine that requires a discrete GPU limits the application to a relatively small segment of PCs. Further, the segmentation effect should ideally be very efficient since it will usually be used along with other intense applications such as gaming with segmentation, and most laptops are constrained in terms of total compute and system-on-chip (SOC) package thermal requirements. Intel and Personify started to explore optimizing an inference engine on Intel® HD Graphics with a goal to meeting these challenges and bringing this technology to the mainstream laptop.
We used Intel® VTune™ Amplifier XE to profile and optimize GPU performance for deep learning inference usage on Intel® 6th Generation Core™ i7 Processors with Intel HD Graphics 530.
Figure 3 shows the baseline execution profile for running the inference workload on a client PC. Even though the application is using the GPU for the deep learning algorithm, the performance lags in its requirements. The total time to run a non-optimized inference algorithm on Intel HD Graphics is about three seconds for compute and the GPU is 70 percent stall.
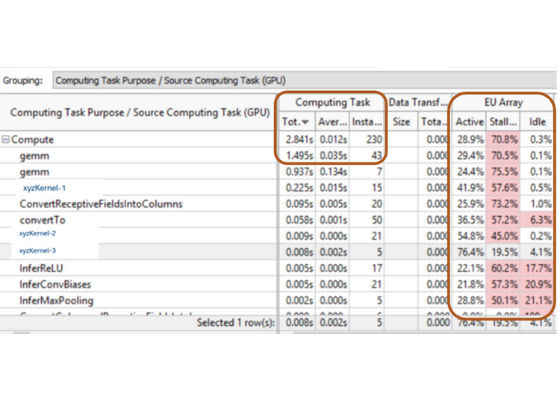
Figure 3. Intel® VTune™ analyzer GPU profile for segmentation (baseline)
The two most important columns that stand out are total time in general matrix-to-matrix multiplication (GEMM) and execution unit (EU) stalls. Without optimization, the deep learning inference engine is very slow for image segmentation in a video conferencing scenario on Intel HD Graphics. Our task was to hit maximum performance from an Intel® GPU on a mainstream consumer laptop.
Optimization: Optimizing a matrix-to-matrix multiplication kernel and increasing EU active time were top priority.
Figure 4 shows the default pipeline of convolutional neural network.
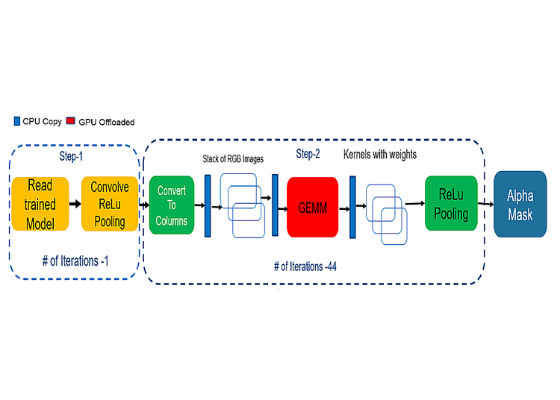
Figure 4. Default deep learning pipeline
We identified several items for deep learning inferencing on Intel HD Graphics (Figure 5).
- CPU Copies – Algorithm is using CPU to copy data from CPU to GPU for processing at every deep learning layer.
- GEMM Convolution Algorithm – based on OpenCV* and OpenCL™.
- Convert to Columns – Uses extra steps and needs extra memory.
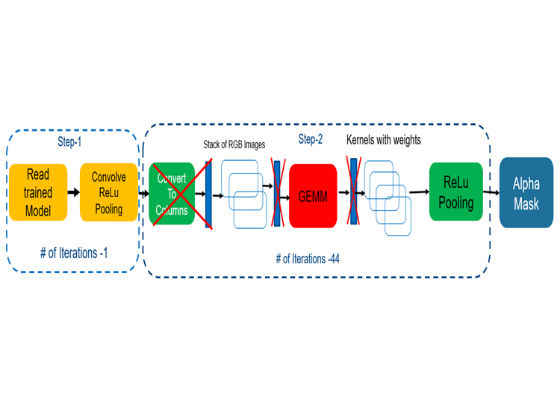
Figure 5. Remove extra copies (using spatial convolution)
We replaced GEMM convolution with spatial convolution, which helped to avoid additional memory copies and produced code that was optimized for speed. We overcame dependencies on reading individual kernels in this architecture by auto-tuning the mechanism (see Figure 6).
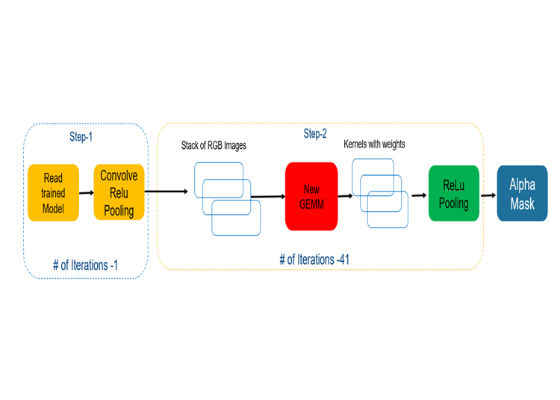
Figure 6. New simple architecture
Result: Our testing on Intel® 6th Generation Core™ i7 Processors with Intel HD Graphics 530 shows 13x better performance on total time (2.8 seconds vs. 0.209 seconds) with about 69.6 percent GPU utilization and ~8.6x performance gain (1.495seconds vs. 0.173 seconds) in GEMM kernels (Figure 7 vs. Figure 3), thus increasing quality real-time segmentation as frame rate is increased.
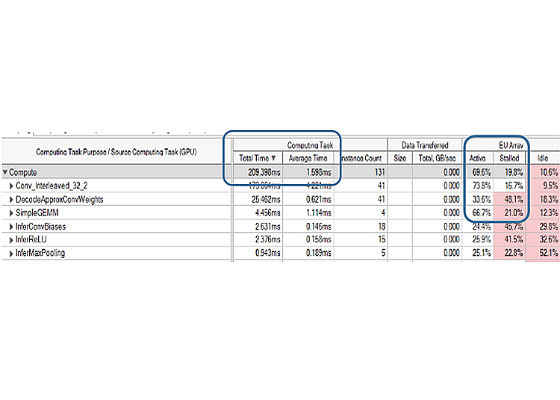
Figure 7. Intel® VTune™ analyzer GPU profile for segmentation (after optimization)
To support mobile usage, battery life is another important metric for a laptop. Bringing high-performance, deep algorithms to a client, at the cost of higher power consumption, impacts the user experience. We analyzed estimated battery power consumption using the Intel® Power Gadget tool during 120 seconds of total video conference workload.
Power Utilization for Personify Application
- GPU Power Utilization 5.5W
- Package SOC Power 11.28W
Summary: We are witnessing a reshuffling of compute partitioning between cloud data centers and clients in favor of moving applications of deep learning models to the client. Local model deployment also has the advantage of latency overhead and keeping personal data local to the device, and thus protecting privacy. Intel processor-based platforms enable high-end CPU and GPUs to provide inference engine applications on clients that cover big, consumer-based ecosystems.
For more such intel IoT resources and tools from Intel, please visit the Intel® Developer Zone
Source:https://software.intel.com/en-us/articles/background-on-ai-and-the-move-to-the-edge



