
Introduction
Do you realize how much performance you are losing out on by not coding for the graphics processing unit (GPU)? Also referred to as “the other side of the chip,” the GPU portion available in many modern-day Intel® processors could be the star of the show for video encoding, image rendering, Fast Fourier Transforms (FFTs), and more. While it has become second-nature for software developers to use parallelization techniques such as vectorized libraries, SIMD intrinsics, and so on, many developers do not realize that the GPU is available as a very capable accelerator. In fact there’s a whole topic of “Heterogeneous Programming” that refers to the process of re-architecting software to efficiently use multiple compute engines with different strengths.
Figure 1 shows a quick history of the development of GPU power within the Intel® Core™ processor.
Figure 1. Development of GPU power on the Intel® Core™ processor.
The Problems
Code that would run well on the GPU must be specifically written and organized for the GPU. While there are well-established compiler flags available for parallelization for the CPU (-axAVX, -axSSE4.2, -xSSE2, etc.), offloading to the GPU is fundamentally more difficult because it requires a different paradigm than what has been established for CPUs since software development began in the 1940s. Because of this, the CPUs may be reaching performance plateaus, while an entirely separate processor that could be running the algorithms much faster using much less power sits mostly idle.
Because heterogeneous programming requires rethinking algorithms, many developers opt for simply maintaining CPU code with incremental improvements. However, the leap to heterogeneous is very doable if you keep a few heuristics in mind.
Getting to the "Other Side"
If your dreams for what your application can do are limited by CPU performance or power constraints, heterogeneous programming may be for you. Start fine-tuning your application with Intel® VTune™ Amplifier to determine hotspots. However, this is just a first step. Understand what is really required by the algorithm, understand the types of engines you can target, and a more efficient approach will probably emerge.
Intel® Core™ processors are heterogeneous. There are at least three types of engines available on most Intel® processors: CPU, execution unit (EU), and general-purpose GPU (GPGPU), and fixed function for media (see Figure 2).
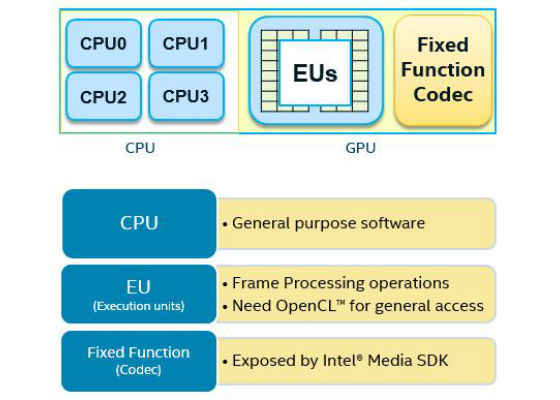
Figure 2. Evolution of heterogeneous architecture.
Heterogeneous programming requires software developers to have a very good understanding of what algorithms run the best on each of the above components. Are you doing video encoding, decoding, or downsizing? Take a look at what the VDBox/MFX fixed function can do. If there is a match, let the fixed function take it. For this short list, that is the best performance/power option and offloading will leave resources for other work. For algorithm components not on this list, here are some basic characteristics that are well-suited for EU engines:
- Grid/mesh-based algorithms
- Algorithms that can be parallelized and have a large memory bandwidth
- Algorithms that are not branchy
Here are a few examples of software and algorithms that are well-suited to run specifically on the EUs:
- Resize (especially upscaling). Note that downscaling is already covered by a fixed function.
- Image filters, ranging from simple color conversions and video effects to complex computer vision or FFT-based algorithms
If you have an existing code-base that consists of algorithms that would be well-suited for the GPU, rather than doing a complete re-write, take a look at ROI – for current algorithm speedup as well as all of the new things you could do by taking full advantage of all of the capabilities of the HW.
If you are just beginning with the design of your application, start by determining which algorithms fit into a SIMD format according to the types of algorithms listed above. OpenCL™ kernels work best for data parallel work without branches. There is overhead to launching a kernel, but it may be possible to still offload small calculations by figuring out a way to coalesce them, or it may even be possible to launch once and just have the kernel wait for new input (versus relaunching each time something needs to be calculated).
Software Toolsets for Programming the GPU
In order to offload your algorithms onto the GPU, you need GPU-aware tools. Intel provides the Intel® SDK for OpenCL™ and the Intel® Media SDK (see Figure 3).
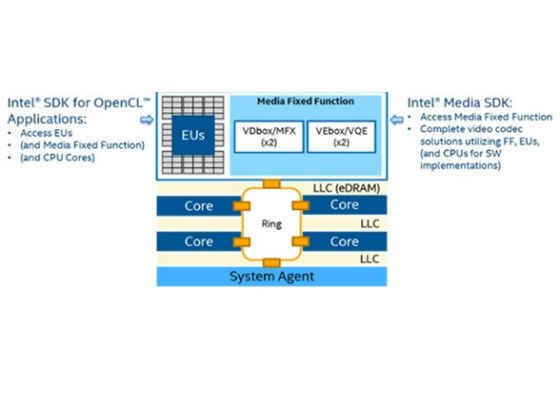
Figure 3. Intel® SDK for OpenCL™ and Intel® Media SDK Interoperability.
Using the Intel® Media SDK for Encoding and Decoding
The Intel Media SDK is a cross-platform API that developers can use for creating media applications on Windows* and Linux*. The Intel Media SDK comes with a set of code samples that demonstrate how to use the API to build applications that require fast video playback, encode, processing, media format conversion and video conferencing.
The Intel Media SDK libraries are built on top of Microsoft DirectX*, DirectX Video Acceleration (DVXA) APIs, VA-API and platform graphics drivers. The main focus of the SDK is on media pipeline components that are commonly used and often in most need of acceleration, such as:
- Decoding from video streaming formats (H.264, MPEG*-2, VC-1, and JPEG*/Motion JPEG,HEVC)
- Selected video-frame processing operations
- Encoding streaming formats (H.264, MPEG-2, HEVC)
- Audio encode/decode and container split/muxing
The Intel Media SDK comes with a set of tutorials and code samples that demonstrate use of the SDK APIs.
Use OpenCL™ for Fixed Operations
OpenCL is the open-standard for parallel programming of heterogeneous systems, allowing developers to leverage the technology and fully customize their solutions. When you boil it down, the Intel Media SDK only does three things: decode, encode, and a create a short list of frame-processing operations. OpenCL opens the door to extend these fixed operations in innovative ways.
A good way to get started with OpenCL development is with Intel® SDK for OpenCL Applications. It includes the Intel® Code Builder for OpenCL™ API, which is a software development tool that enables development of OpenCL applications. If you are working with pre-existing code, your project can be converted to an OpenCL project from within the Intel SDK for OpenCL interface.
OpenCL is developed by multiple companies through the Khronos* OpenCL committee.
For more such intel Machine Learning and tools from Intel, please visit the Intel® Machine Learning Code
Source: https://software.intel.com/en-us/blogs/2016/06/15/offload-gpu-cpu



