
In some high-quality games, an avatar may have facial expression animation. These animations are usually pre-generated by the game artist and replayed in the game according to the fixed story plot. If players are given the ability to animate that avatar’s face based on their own facial motion in real time, it may enable personalized expression interaction and creative game play. Intel® RealSense™ technology is based on a consumer-grade RGB-D camera, which provides the building blocks like face detection and analysis functions for this new kind of usage. In this article, we introduce a method for an avatar to simulate user facial expression with the Intel® RealSense™ SDK and also provide the sample codes to be downloaded.
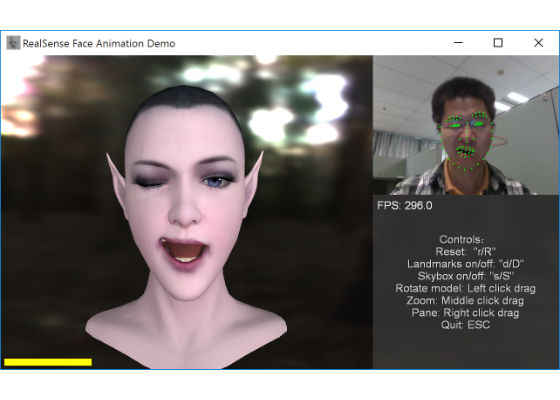
Figure 1: The sample application of Intel® RealSense™ SDK-based face tracking and animation.
System Overview
Our method is based on the idea of the Facial Action Coding System (FACS), which deconstructs facial expressions into specific Action Units (AU). AUs are a contraction or relaxation of one or more muscles. With the weights of the AUs, nearly any anatomically possible facial expression can be synthesized.
Our method also assumes that the user and avatar have compatible expression space so that the AU weights can be shared between them. Table 1 illustrates the AUs defined in the sample code.
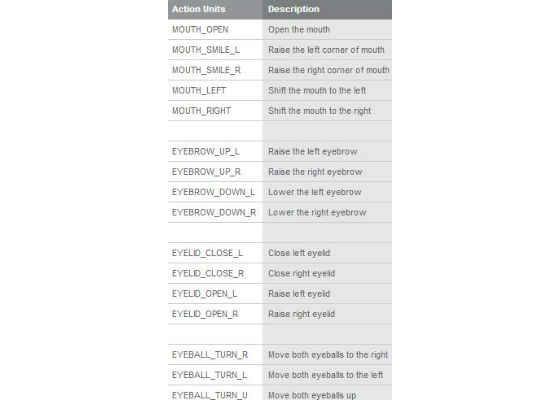
Table 1: The Action Units defined in the sample code.
The pipeline of our method includes three stages: (1) tracking the user face by the Intel RealSense SDK, (2) using the tracked facial feature data to calculate the AU weights of the user’s facial expression, and (3) synchronizing the avatar facial expression through normalized AU weights and corresponding avatar AU animation assets.
Prepare Animation Assets
To synthesize the facial expression of the avatar, the game artist needs to prepare the animation assets for each AU of the avatar’s face.
If the face is animated by a blend-shape rig, the blend-shape model of the avatar should contain the base shape built for a face of neutral expression and the target shapes, respectively, constructed for the face with the maximum pose of the corresponding AU. If a skeleton rig is used for facial animation, the animation sequence must be respectively prepared for every AU. The key frames of the AU animation sequence transform the avatar face from a neutral pose to the maximum pose of the corresponding AU. The duration of the animation doesn’t matter, but we recommend a duration of 1 second (31 frames, from 0 to 30).
The sample application demonstrates the animation assets and expression synthesis method for avatars with skeleton-based facial animation.
In the rest of the article, we discuss the implementation details in the sample code.
Face Tracking
In our method, the user face is tracked by the Intel RealSense SDK. The SDK face-tracking module provides a suite of the following face algorithms:
- Face detection: Locates a face (or multiple faces) from an image or a video sequence, and returns the face location in a rectangle.
- Landmark detection: Further identifies the feature points (eyes, mouth, and so on) for a given face rectangle.
- Pose detection: Estimates the face’s orientation based on where the user's face is looking.
Our method chooses the user face that is closest to the Intel® RealSense™ camera as the source face for expression retargeting and gets this face’s 3D landmarks and orientation in camera space to use in the next stage.
Facial Expression Parameterization
Once we have the landmarks and orientation of the user’s face, the facial expression can be parameterized as a vector of AU weights. To obtain the AU weights, which can be used to control an avatar’s facial animation, we first measure the AU displacement. The displacement of the k-th AU
Dk is achieved by the following formula:

Where Skc is the k-th AU state in the current expression, Skn is the k-th AU state in a neutral expression, and Nk is the normalization factor for k-th AU state.
We measure AU states Skc and Skn in terms of the distances between the associated 3D landmarks. Using a 3D landmark in camera space instead of a 2D landmark in screen space can prevent the measurement from being affected by the distance between the user face and the Intel RealSense camera.
Different users have different facial geometry and proportions. So the normalization is required to ensure that the AU displacement extracted from two users have approximately the same magnitude when both are in the same expression. We calculated Nk in the initial calibration step on the user’s neutral expression, using the similar method to measure MPEG4 FAPU (Face Animation Parameter Unit).
In normalized expression space, we can define the scope for each AU displacement. The AU weights are calculated by the following formula:

Where Dkmax is the maximum of the k-th AU displacement.
Because of the accuracy of face tracking, the measured AU weights derived from the above formulas may generate an unnatural expression in some special situations. In the sample application, geometric constraints among AUs are used to adjust the measured weights to ensure that a reconstructed expression is plausible, even if not necessarily close to the input geometrically.
Also because of the input accuracy, the signal of the measured AU weights is noisy, which may have the reconstructed expression animation stuttering in some special situations. So smoothing AU weights is necessary. However, smoothing may cause latency, which impacts the agility of expression change.
We smooth the AU weights by interpolation between the weight of the current frame and that of previous frame as follows:

Where wi,k is the weight of the k-th AU in i-th frame.
To balance the requirements of both smoothing and agility, the smoothing factor of the i-th frame for AU weights, αi is set as the face-tracking confidence of this frame. The face-tracking confidence is evaluated according to the lost tracking rate and the angle of the face deviating from a neutral pose. The higher the lost tracking rate and bigger deviation angle, the lower the confidence to get accurate tracking data.
Similarly, the face angle is smoothed by interpolation between the angle of the current frame and that of the previous frame as follows:

To balance the requirements of both smoothing and agility, the smoothing factor of the i-th frame for face angle, βi, is adaptive to face angles and calculated by

Where T is the threshold of noise, taking the smaller variation between face angles as more noise to smooth out, and taking the bigger variation as more actual head rotation to respond to.
Expression Animation Synthesis
This stage synthesizes the complete avatar expression in terms of multiple AU weights and their corresponding AU animation assets. If the avatar facial animation is based on a blend-shape rig, the mesh of the final facial expression Bfinal is generated by the conventional blend-shape formula as follows:

Where B0 is the face mesh of a neutral expression, Bi is the face mesh with the maximum pose of the i-th AU.
If the avatar facial animation is based on a skeleton rig, the bone matrices of the final facial expressionSfinal are achieved by the following formula:

Where S0 is the bone matrices of a neutral expression, Ai(wi) is the bone matrices of the i-th AU extracted from this AU’s key-frame animation sequence Ai by this AU’s weight wi.
The sample application demonstrates the implementation of facial expression synthesis for a skeleton-rigged avatar.
Performance and Multithreading
Real-time facial tracking and animation is a CPU-intensive function. Integrating the function into the main loop of the application may significantly degrade application performance. To solve the issue, we wrap the function in a dedicated work thread. The main thread retrieves the new data from the work thread just when the data are updated. Otherwise, the main thread uses the old data to animate and render the avatar. This asynchronous integration mode minimizes the performance impact of the function to the primary tasks of the application.
Running the Sample
When the sample application launches (Figure 1), by default it first calibrates the user’s neutral expression, and then real-time mapping user performed expressions to the avatar face. Pressing the “R” key resets the system when the user wants to or a new user substitutes to control the avatar expression, which will activate a new session including calibration and retargeting.
During the calibration phase—in the first few seconds after the application launches or is reset—the user is advised to hold his or her face in a neutral expression and position his or her head so that it faces the Intel RealSense camera in the frontal-parallel view. The calibration completes when the status bar of face-tracking confidence (in the lower-left corner of the Application window) becomes active.
After calibration, the user is free to move his or her head and perform any expression to animate the avatar face. During this phase, it’s best for the user to keep an eye on the detected Intel RealSense camera landmarks, and make sure they are green and appear in the video overlay.
Summary
Face tracking is an interesting function supported by Intel® RealSense™ technology. In this article, we introduce a reference implementation of user-controlled avatar facial animation based on Intel® RealSense™ SDK, as well as the sample written in C++ and uses DirectX*. The reference implementation includes how to prepare animation assets, to parameterize user facial expression and to synthesize avatar expression animation. Our practices show that not only are the algorithms of the reference implementation essential to reproduce plausible facial animation, but also the high quality facial animation assets and appropriate user guide are important for better user experience in real application environment.
For more such intel resources and tools from Intel on Game, please visit the Intel® Game Developer Zone
Source:https://software.intel.com/en-us/articles/intel-realsense-sdk-based-real-time-face-tracking-and-animation



