
The recent advances in machine learning and artificial intelligence are amazing! It seems like we see something groundbreaking every day, from self-driving cars, to AIs learning complex games. Yet, in order to have real value within a company, data scientists must be able to get their models off of their laptops and deployed within a company’s data pipelines and infrastructure.
Moreover, data scientists should spend their time focused on improving their machine learning applications. They should not have to spend a great deal of time manually keeping their applications up to date with constantly changing production data. They also shouldn’t have to waste their days trying to retroactively identify and track interesting past behavior.
Docker* and Pachyderm* can help data scientists build, deploy, and update machine learning applications on production clusters, distributed processing across large data sets, and track input and output data throughout a data pipeline. In this post we show how to set up a production-ready machine learning workflow with Intel® Nervana™ technology, neon*, and Pachyderm.
Intel® Nervana™ technology and neon*
Intel Nervana technology with neon is the “world’s fastest deep learning framework.” It is open source (seeGitHub*), Python* based, and includes a really nice set of libraries for developing deep learning models.
You can get started developing by checking out the neon documentation and installing neon locally:
git clone https://github.com/NervanaSystems/neon.git
cd neon; make
Then you are ready to try out some examples.
Pachyderm*
Pachyderm is an open-source framework that provides data versioning and data pipelining built on containers (specifically, Docker containers). With Pachyderm, you can create language-agnostic data pipelines where the data input and output of each stage of your pipeline are version controlled in Pachyderm; think Git for data. You can view diffs of your data and collaborate with teammates using Pachyderm commits and branches. Also, if your data pipeline generates an unexpected result, you can debug or validate it by understanding the historical processing steps that lead to the result (or even reproducing them exactly).
Pachyderm can also easily parallelize your computation by only showing a subset of your data to each container that is part of a Pachyderm pipeline. A single node either sees a slice of each file (a map job) or a whole single file (a reduce job). The data itself can live in an object store of your choice (for example, S3), and Pachyderm smartly assigns different pieces of data to be processed by different containers.
Pachyderm clusters can run on any cloud, but you can also experiment with Pachyderm locally. After installing the Pachyderm CLI tool, Pachctl, and installing and running Minikube*, Pachyderm can be installed locally in a single command:
pachctl deploy local
Using Docker-ized neon
In order to utilize Neon in a production Pachyderm cluster (or to just easily deploy it), we need to be able to Docker-ize Neon. Docker allows us to package up our machine learning application in a portable image that we can run as a container on any system that has Docker. Thus, it makes our machine learning application portable.
Thankfully, there are already publically available Docker images for neon, so let’s see how this image works. Assuming you have Docker installed and you are running CPU only, you can get Docker-ized neon by pulling the following image (which is endorsed by the neon team):
docker pull kaixhin/neon
Then, to experiment with neon inside Docker interactively, you could run:
docker run -it kaixhin/neon /bin/bash
This will open a bash shell in a running instance of the neon image (or a container) in which you could create and run Python programs that utilize neon. You could also navigate to the Neon `examples` directory to run the neon example models inside Docker.
However, let’s say that we already have a Python program `mymodel.py` that utilizes neon, and we want to run that program in Docker. We want to create a custom Docker image that includes our program. To do this, you would simply create a file called `Dockerfile` that lives with your `mymodel.py` script:
my_project_directory
├── mymodel.py
└── Dockerfile
This `Dockerfile` will tell Docker how to build a custom image that includes both neon and our custom neon-based script. For a case where `mymodel.py` only utilizes Neon and the Python standard library, the `Dockerfile` can simply be:
FROM kaixhin/neon
ADD mymodel.py /
Then, to build your custom Docker image, run:
docker build -t mycustomimage .
from the root of your project. The resulting image could then be used to run your neon model on any machine running Docker by running:
docker run -it mycustomimage python /mymodel.py
Distributing Docker-ized neon on a Production Cluster
Running Docker-ized neon as mentioned above is great for portability, but we don’t necessarily want to manually log in to production machines to deploy single instances of our model. We want to integrate our neon model into a distributed data pipeline running on a production cluster, and ensure that our model can scale over large data sets. This is where Pachyderm can help us.
We are going to implement both model training and inference into a sustainable, production-ready data pipeline. To illustrate this process, we are going to utilize an example LSTM model that predicts the sentiment of movie reviews based on a training data set from IMDB. More information about this model is available.
Training
Pachyderm lets us create data pipelines with Docker containers as the processing stages. These containerized processing stages have versioned data in data repositories as input, and they output to a corresponding data repository. Thus, the input/output data of each processing stage is versioned in Pachyderm.
We will set up one of these pipeline stages to perform the training of our LSTM model. This model pipeline stage will take a labeled training dataset `labeledTrainData.tsv` as input, and output a persisted (or saved to disk) version of the trained model as a set of model parameters, `imdb.p`, and a model vocab,
`imdb.vocab`. The actual processing for this stage will use a python script, `train.py`, and is already included in the public kaixhin/neon Docker image.
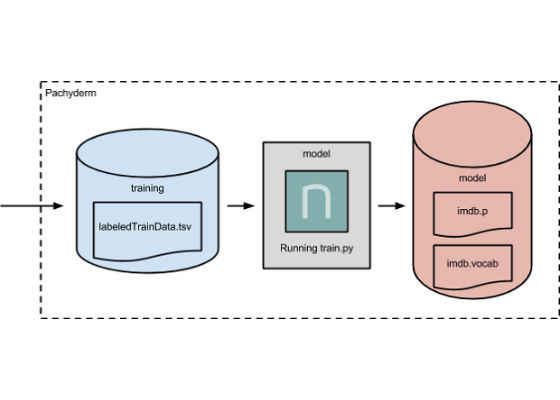
To create the above pipeline, we first need to create the training data repository that will be input to ourmodel pipeline stage:
pachctl create-repo training
We can then confirm that the repository was created by:
pachctl list-repo
Next, we can create the model pipeline stage to process the data in the training repository. To do this, we just need to provide Pachyderm with a JSON pipeline specification that tells Pachyderm how to process the data. In this case, the JSON specification looks like this:
{
"pipeline": {
"name": "model"
},
"transform": {
"image": "kaixhin/neon",
"cmd": [
"python",
"examples/imdb/train.py",
"-f",
"/pfs/training/labeledTrainData.tsv",
"-e",
"2",
"-eval",
"1",
"-s",
"/pfs/out/imdb.p",
"–vocab_file",
"/pfs/out/imdb.vocab"
]
},
"inputs": [
{
"repo": {
"name": "training"
},
"glob": "/"
}
]
}
This may seem complicated, but it really just says a few things: (1) create a pipeline stage called model, (2) use the kaixhin/neon Docker image for this pipeline stage, (3) run the provided Python cmd to process data, and (4) process any data in the input repository training.
There are other options that we will ignore for the time being, but these fields are all discussed in the Pachyderm docs.
Once we have this JSON file (saved in `train.json`), creating the above pipeline on a production-ready Pachyderm cluster is as simple as:
pachctl create-pipeline -f train.json
Now, Pachyderm knows that it should perform the above processing, which in our case is training a neon model on the training data in the training repository. In fact, because Pachyderm is versioning data and knows what data is new, Pachyderm will keep our model output (versioned in a corresponding modelrepository created by Pachyderm) in sync with the latest updates to our training data. When we commit new training data into the training repository, Pachyderm will automatically update our persisted, trained model in the model repository.
However, we haven’t actually put any data into the training repository yet, so let’s go ahead and do that. Specifically, let’s put a file `labeledTrainData.tsv`, in the master branch of our training repository (again with Git-like semantics):
pachctl put-file training master labeledTrainData.tsv -c -f labeledTrainData.tsv
Now, when you run `pachctl list-repo`, you will see that data has been added to the training repository. Moreover, if you run `pachctl list-job`, you will see that Pachyderm has started a job to process the training data and output our persisted model to the model repository. Once this job finishes, we have trained our model. We could then re-train our production model any time by pushing new training data into the training repository or updating our pipeline with a new image for the model pipeline stage.
To confirm that our model has been trained, you should see both `imdb.p` and `imdb.vocab` in an output data repository created for the pipeline stage by Pachyderm:
pachctl list-file model master
Note, we actually told Pachyderm what to write out to this repository by saving our files to Pachyderm’s magic `/pfs/out` directory, which specifies the output repository corresponding to our processing stage.
Prediction/Inference
Next, we want to add an inference stage to our production pipeline which utilizes our versioned, persisted model. This inference stage will take new movie reviews, which the model hasn’t seen yet as input, and output the inferred sentiment of those movie reviews using our persisted model. This inference will again run a Python script, `auto_inference.py`, that utilizes neon.
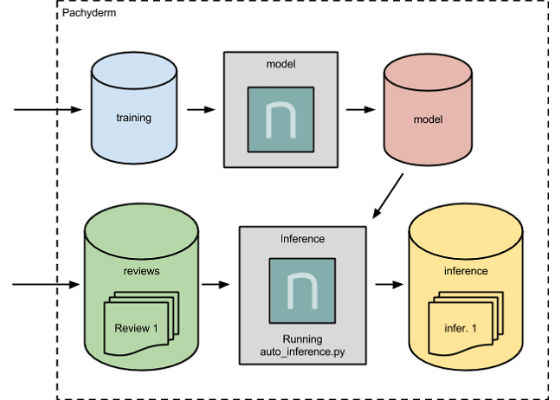
To create this inference pipeline stage, we first need to create the Pachyderm repository that will store and version our input reviews:
pachctl create-repo reviews
Then we can create another JSON blog that will tell Pachyderm how to perform the processing for the inference stage:
{
"pipeline": {
"name": "inference"
},
"transform": {
"image": "dwhitena/neon-inference",
"cmd": [
"python",
"examples/imdb/auto_inference.py",
"–model_weights",
"/pfs/model/imdb.p",
"–vocab_file",
"/pfs/model/imdb.vocab",
"–review_files",
"/pfs/reviews",
"–output_dir",
"/pfs/out"
]
},
"parallelism_spec": {
"strategy": "CONSTANT",
"constant": "1"
},
"inputs": [
{
"repo": {
"name": "reviews"
},
"glob": "/*"
},
{
"repo": {
"name": "model"
},
"glob": "/"
}
]
}
This is similar to our last JSON specification except, in this case, we have two input repositories (thereviews and the model) and we are using a different Docker image that contains `auto_inference.py`. The Dockerfile for this image can be found here.
To create the inference stage, we simply run:
pachctl create-pipeline -f infer.json
Now whenever new reviews are pushed into the reviews repository, Pachyderm will see these new reviews, perform the inference, and output the inference results to a corresponding inference repository.
In fact, let’s say that we have already pushed a million reviews into the reviews repository. If we push one more review into the repository, Pachyderm understands that only the one review is new and will only update the results for the one new review. There is no need to process all of our data again, because Pachyderm isdiff aware and keeps our processing in sync with the latest changes to our data.
Our inference pipeline actually works as both a batch and streaming inference pipeline. You could push many reviews into the reviews repository at periodic times to perform batch inferences on those batches of reviews. However, you could also stream individual reviews into the repository as they are created. Either way, Pachyderm automatically performs the inferences on the new reviews and outputs the results.
Implications
By combining our training and inference into a data pipeline processing versioned data, we have set ourselves up to take advantage of some pretty valuable functionality. At any time, a data scientist or engineer could update the training data set utilized by the model to trigger the creation of a newly persisted, versioned model in our model repository. When the model is updated, any new reviews coming into the reviewsrepository will be processed with the updated model.
Further, old predictions can be recomputed with the updated model, or new models could be tested on previous versioned input. No more manual updates to historical results or worrying about how to swap-out models in production!
Furthermore, although we skipped over it above, each pipeline stage in our Pachyderm pipeline is individually scalable via a parallelism specification. If we were suddenly receiving tens of thousands of reviews at a time, we could adjust the parallelism of our inference pipeline stage by setting:
"parallelism_spec": {
"strategy": "CONSTANT",
"constant": "10"
}
or by setting our constant to any other number above one. This will tell Pachyderm to spin up multiple workers to perform our inference (10 in the above example), and Pachyderm will automatically split our review data between the workers for parallel processing.
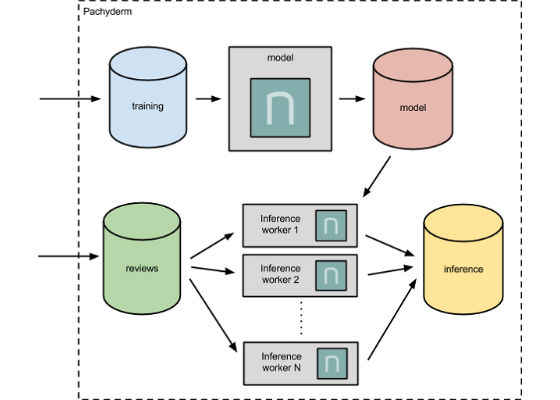
We can focus on developing and improving your modeling and let Pachyderm worry about distributing our inference on the production cluster. This also keeps our implementations simple and readable. We can scale the Python/neon scripts we develop on our local machine to production-scale data without having to think about data sharding, complicating your code with frameworks such as Dask*, or even transferring your modeling to another language or framework for production use.
Optimizations
Although Pachyderm takes care of the data sharding, parallelism, and orchestration pieces for us, there are several nice optimizations that we can take advantage of in this pipeline.
First, both our training and inference stages are running Python importing Neon. As such, we could further optimize our processing without even changing a line of code, by using Intel® Distribution for Python*. This automatically integrates the powerful Intel® Math Kernel Library (Intel® MKL), Intel® Data Analytics Acceleration Library (Intel® DAAL) and pyDAAL, Intel® MPI Library, and Intel® Threading Building Blocks (Intel® TBB) into core Python packages including NumPy*, SciPy*, and pandas*.
In fact, to take advantage of Intel optimized Python within Pachyderm, we could simply replace our current Neon image with a custom Docker image based on one of the public Intel Python images. An example of such an image could be built from a Dockerfile. We would just need to add a Python script of our choice to the image (as shown here), upload the image to DockerHub (or another registry), and change the name of the referenced image in our Pachyderm pipeline specification.
Also, we could choose to deploy our pipeline on Intel® Xeon Phi™ processor architecture, which would automatically give us more of a boost for machine learning workflows. These chips are further optimized for the types of processing involved in deep learning training and inference.
For more such intel IoT resources and tools from Intel, please visit the Intel® Developer Zone
Source:https://software.intel.com/en-us/articles/distributed-docker-ized-deep-learning-with-intel-nervana-technology-neon-and-pachyderm



