
Deep neural network (DNN) training is computationally intensive and can take days or weeks on modern computing platforms. In the recent article, Single-node Caffe Scoring and Training on Intel® Xeon® E5 Family, we demonstrated a tenfold performance increase of the Caffe* framework on the AlexNet* topology and reduced the training time to 5 days on a single node. Intel continues to deliver on the machine learning vision outlined in Pradeep Dubey’s Blog, and in this technical preview, we demonstrate how the training time for Caffe can be reduced from days to hours in a multi-node, distributed-memory environment.
This article includes preview package that has limited functionality and is not intended for production use. Discussed features are now available as part of Intel MKL 2017 and Intel’s fork of Caffe.
Caffe is a deep learning framework developed by the Berkeley Vision and Learning Center (BVLC) and one of the most popular community frameworks for image recognition. Caffe is often used as a benchmark together with AlexNet*, a neural network topology for image recognition, and ImageNet*, a database of labeled images.
The Caffe framework does not support multi-node, distributed-memory systems by default and requires extensive changes to run on distributed-memory systems. We perform strong scaling of the synchronous minibatch stochastic gradient descent (SGD) algorithm with the help of Intel® MPI Library. Computation for one iteration is scaled across multiple nodes, such that the multi-threaded multi-node parallel implementation is equivalent to the single-node, single-threaded serial implementation.
We use three approaches—data parallelism, model parallelism, and hybrid parallelism—to scale computation. Model parallelism refers to partitioning the model or weights into nodes, such that parts of weights are owned by a given node and each node processes all the data points in a minibatch. This requires communication of the activations and gradients of activations, unlike communication of weights and weight gradients, as is the case with data parallelism.
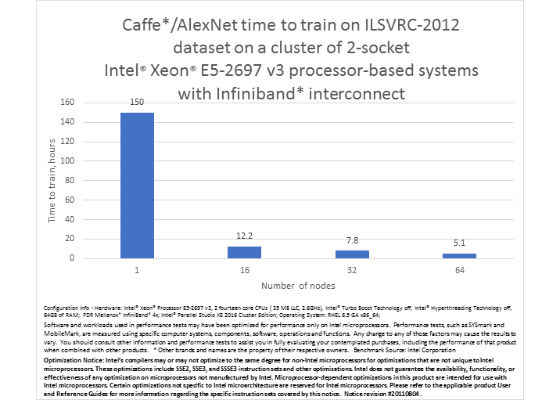
With this additional level of distributed parallelization, we trained AlexNet on the full ImageNet Large Scale Visual Recognition Challenge 2012 (ILSVRC-2012) dataset and reached 80% top-5 accuracy in just over 5 hours on a 64-node cluster of systems based on Intel® Xeon® processor E5 family.
Getting Started
While we are working to incorporate the new functionality outlined in this article into future versions of Intel®Math Kernel Library (Intel® MKL) and Intel® Data Analytics Acceleration Library (Intel® DAAL), you can use the technology preview package attached to this article to reproduce the demonstrated performance results and even train AlexNet on your own dataset. The preview includes both the single-node and the multi-node implementations. Note that the current implementation is limited to the AlexNet topology and may not work with other popular DNN topologies.
The package supports the AlexNet topology and introduces the ‘intel_alexnet’ and ‘mpi_intel_alexnet’ models, which are similar to ‘bvlc_alexnet’ with the addition of two new ‘IntelPack’ and ‘IntelUnpack’ layers, as well as the optimized convolution, pooling, normalization layers, and MPI-based implementations for all these layers. We also changed the validation parameters to facilitate vectorization by increasing the validation minibatch size from 50 to 256 and reducing the number of test iterations from 1,000 to 200, thus keeping constant the number of images used in the validation run. The package contains the ‘intel_alexnet’ model in these folders:
- models/intel_alexnet/deploy.prototxt
- models/intel_alexnet/solver.prototxt
- models/intel_alexnet/train_val.prototxt.
- models/mpi_intel_alexnet/deploy.prototxt
- models/mpi_intel_alexnet/solver.prototxt
- models/mpi_intel_alexnet/train_val.prototxt.
- models/mpi_intel_alexnet/train_val_shared_db.prototxt
- models/mpi_intel_alexnet/train_val_split_db.prototxt
Both the ’intel_alexnet’ and the ’mpi_intel_alexnet’ models allow you to train and test the ILSVRC-2012 training set.
To start working with the package, ensure that all the regular Caffe dependencies and Intel software tools listed in the System Requirements and Limitations section are installed on your system.
Running on Single Node
1. Unpack the package.
2. Specify the paths to the database, snapshot location, and image mean file in these ‘intel_alexnet’ model files:
- models/intel_alexnet/deploy.prototxt
- models/intel_alexnet/solver.prototxt
- models/intel_alexnet/train_val.prototxt
3. Set up a runtime environment for the software tools listed in the System Requirements and Limitations section.
4. Add the path to ./build/lib/libcaffe.so to the LD_LIBRARY_PATH environment variable.
5. Set the threading environment as follows:
- $> export OMP_NUM_THREADS=<N_processors * N_cores>
- $> export KMP_AFFINITY=compact,granularity=fine
Note: OMP_NUM_THREADS must be an even number equal to at least 2.
1. Run timing on a single node using this command:
$> ./build/tools/caffe time \
-iterations <number of iterations> \
–model=models/intel_alexnet/train_val.prototxt
2. Run training on a single node using this command:
$> ./build/tools/caffe train \
–solver=models/intel_alexnet/solver.prototxt
Running on Cluster
1. Unpack the package.
2. Set up a runtime environment for the software tools listed in the System Requirements and Limitations section.
3. Add the path to ./build-mpi/lib/libcaffe.so to the LD_LIBRARY_PATH environment variable.
4. Set the NP environment variable to the number of nodes to be used, as follows:
$> export NP=<number-of-mpi-ranks>
Note: the best performance is achieved with one MPI rank per node.
1. Create a node file in the root directory of the application with the name of x${NP}.hosts. For instance, for IBM* Platform LSF*, run the following command:
$> cat $PBS_NODEFILE > x${NP}.hosts
1. Specify the paths to the database, snapshot location, and image mean file in the following ‘mpi_intel_alexnet’ model files:
- models/mpi_intel_alexnet/deploy.prototxt,
- models/mpi_intel_alexnet/solver.prototxt,
- models/mpi_intel_alexnet/train_val_shared_db.prototxt
Note: on some system configurations, performance of a shared-disk system may become a bottleneck. In this case, pre-distributing the image database to compute nodes is recommended to achieve best performance results. Refer to the readme files included with the package for instructions.
1. Set the threading environment as follows:
$> export OMP_NUM_THREADS=<N_processors * N_cores>
$> export KMP_AFFINITY=compact,granularity=fine
Note: OMP_NUM_THREADS must be an even number equal to at least 2.
1. Run timing using this command:
$> mpirun -nodefile x${NP}.hosts -n $NP -ppn 1 -prepend-rank \
./build/tools/caffe time \
-iterations <number of iterations> \
–model=models/mpi_intel_alexnet/train_val.prototxt
1. Run training using this command:
$> mpirun -nodefile x${NP}.hosts -n $NP -ppn 1 -prepend-rank \
./build-mpi/tools/caffe train \
–solver=models/mpi_intel_alexnet/solver.prototxt
For more such intel Machine Learning and tools from Intel, please visit the Intel® Machine Learning Code
Source: https://software.intel.com/en-us/articles/caffe-training-on-multi-node-distributed-memory-systems-based-on-intel-xeon-processor-e5