
Introduction
A lot of buzz talks over Internet which suggests that machine learning and Artificial Intelligence (AI) are basically the same thing, but this is a misunderstanding. Both machine learning and Knowledge Reasoning have the same concern: the construction of intelligent software.
However, while machine learning is an approach to AI based on algorithms whose performance improve as they are exposed to more data over time, Knowledge Reasoning is a sibling approach based on symbolic logic.
Knowledge Reasoning’s strategy is usually developed by using functional and logic based programming languages such as Lisp*, Prolog*, and ML* due to their ability to perform symbolic manipulation. This kind of manipulation is often associated with expert systems, where high level rules are often provided by humans and used to simulate knowledge, avoiding low-level language details. This focus is called Mind Centered. Commonly, some kind of (backward or forward) logical inference is needed.
Machine learning, on its turn, is associated with low-level mathematical representations of systems and a set of training data that lead the system toward performance improvement. Once there is no high-level modeling, the process is called Brain Centered. Any language that facilitates writing vector algebra and numeric calculus over an imperative paradigm works just fine. For instance, there are several machine learning systems written in Python* simply because the mathematical support is available as libraries for such programming language.
This article aims to explore what happens when Intel solutions support functional and logic programming languages that are regularly used for AI. Despite machine learning systems success over the last two decades, the place for traditional AI has neither disappeared nor diminished, especially in systems where it is necessary to explain why a computer program behaves the way it does. Hence, it is not feasible to believe that next generations of learning systems will be developed without high-level descriptions, and thus it is expected that some problems will demand symbolical solutions. Prolog and similar programming languages are valuable tools for solving such problems.
As it will be detailed below, this article proposes a Prolog interpreter recompilation using Intel® C++ Compiler and libraries in order to evaluate their contribution to logic based AI. The two main products used are Intel® Parallel Studio XE Cluster Edition and SWI-Prolog interpreter. An experiment with a classical AI problem is also presented.
Building Prolog for Intel® Architecture
1. The following description uses a system equipped with: Intel® Core™ i7 4500U@1.8 GHz processor, 64 bits, Ubuntu 16.04 LTS operating system, 8GB RAM, and hyper threading turned on with 2 threads per core (you may check it by typing sudo dmidecode -t processor | grep -E '(Core
Count|Thread Count)') . Different operating systems may require minor changes.
2. Preparing the environment.
Optimizing performance on hardware is an iterative process. Figure 1 shows a flow chart describing how the various Intel tools help you in several stages of such optimization task.
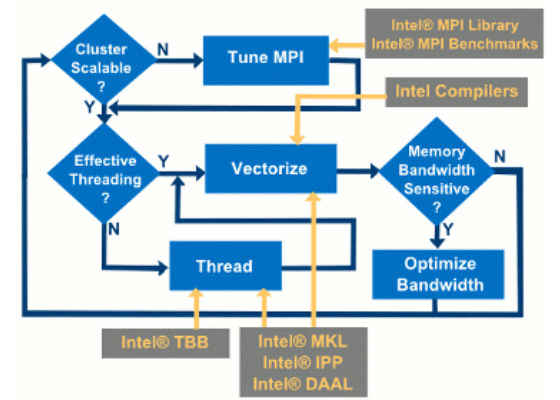
Figure 1: Optimizing performance flowchart and libraries. Extracted from Intel® Parallel Studio documentation1.
The most convenient way to install Intel tools is downloading and installing Intel® Parallel Studio XE 2017. Extracting the .tgz file, you will obtain a folder called parallel_studio_xe_2017update4_cluster_edition_online (or similar version). Open the terminal and then choose the graphical installation:
<user>@<host>:~% cd parallel_studio_xe_2017update4_cluster_edition_online
<user>@<host>:~/parallel_studio_xe_2017update4_cluster_edition_online% ./install_GUI.sh
Although you may prefer to perform a full install, this article will choose a custom installation with components that are frequently useful for many developers. It is recommended that these components also be installed to allow further use of such performance libraries in subsequent projects.
- Intel® Trace Analyzer and Collector
- Intel® Advisor
- Intel® C++ Compiler
- Intel® Math Kernel Library (Intel® MKL) for C/C++
- Intel® Threading Building Blocks (Intel® TBB)
- Intel® Data Analytics Acceleration Library (Intel® DAAL)
- Intel® MPI Library
The installation is very straight-forward, and it does not require many comments to be made. After finishing such task, you must test the availability of Intel® C++ Compiler by typing in your terminal:
<user>@<host>:~% cd ..
<user>@<host>:~% icc –version
icc (ICC) 17.0.4 20170411
If the icc command was not found, it is because the environment variables for running the compiler environment were not set. You must do it by running a predefined script with an argument that specifies the target architecture:
<user>@<host>:~% source /opt/intel/compilers_and_libraries/linux/bin/compilervars.sh -arch intel64 -platform linux
If you wish, you may save disk space by doing:
<user>@<host>:~% rm -r parallel_studio_xe_2017update4_cluster_edition_online
3. Building Prolog.
This article uses the SWI-Prolog interpreter2, which is covered by the Simplified BSD license. SWI-Prolog offers a comprehensive free Prolog environment. It is widely used in research and education as well as commercial applications. You must download the sources in .tar.gz format. At the time this article was written, the available version is 7.4.2. First, decompress the download file:
<user>@<host>:~% tar zxvf swipl-<version>.tar.gz
Then, create a folder where the Prolog interpreter will be installed:
<user>@<host>:~% mkdir swipl_intel
After that, get ready to edit the building variables:
<user>@<host>:~% cd swipl-<version>
<user>@<host>:~/swipl-<version>% cp -p build.templ build
<user>@<host>:~/swipl-<version>% <edit> build
At the build file, look for the PREFIX variable, which indicates the place where SWI-Prolog will be installed. You must set it to:
PREFIX=$HOME/swipl_intel
Then, it is necessary to set some compilation variables. The CC variable must be changed to indicate that Intel® C++ Compiler will be used instead of other compilers. The COFLAGS enables optimizations for speed. The compiler vectorization is enabled at –O2. You may choose higher levels (–O3), but the suggested flag is the generally recommended optimization level. With this option, the compiler performs some basic loop optimizations, inlining of intrinsic, intra-file interprocedural optimization, and most common compiler optimization technologies. The –mkl=parallel option allows access to a set of math functions that are optimized and threaded to explore all the features of the latest Intel® Core™ processors. It must be used with a certain Intel® MKL threading layer, depending on the threading option provided. In this article, the Intel® TBB is such an option and it is used by choosing –tbb flag. At last, the CMFLAGS indicates the compilation will create a 64-bit executable.
export CC="icc"
export COFLAGS="-O2 -mkl=parallel -tbb"
export CMFLAGS="-m64"
Save your build file and close it.
Note that when this article was written, SWI-Prolog was not Message Passing Interface (MPI) ready3. Besides, when checking its source-code, no OpenMP* macros were found (OMP) and thus it is possible that SWI-Prolog is not OpenMP ready too.
If you already have an SWI-Prolog instance installed on your computer you might get confused with which interpreter version was compiled with Intel libraries, and which was not. Therefore, it is useful to indicate that you are using the Intel version by prompting such feature when you call SWI-Prolog interpreter. Thus, the following instruction provides a customized welcome message when running the interpreter:
<user>@<host>:~/swipl-<version>% cd boot
<user>@<host>:~/swipl-<version>/boot% <edit> messages.pl
Search for:
prolog_message(welcome) –>
[ 'Welcome to SWI-Prolog (' ],
prolog_message(threads),
prolog_message(address_bits),
['version ' ],
prolog_message(version),
[ ')', nl ],
prolog_message(copyright),
[ nl ],
prolog_message(user_versions),
[ nl ],
prolog_message(documentaton),
[ nl, nl ].
and add @ Intel® architecture by changing it to:
prolog_message(welcome) –>
[ 'Welcome to SWI-Prolog (' ],
prolog_message(threads),
prolog_message(address_bits),
['version ' ],
prolog_message(version),
[ ') @ Intel® architecture', nl ],
prolog_message(copyright),
[ nl ],
prolog_message(user_versions),
[ nl ],
prolog_message(documentaton),
[ nl, nl ].
Save your messages.pl file and close it. Start building.
<user>@<host>:~/swipl-<version>/boot% cd ..
<user>@<host>:~/swipl-<version>% ./build
The compilation performs several checking and it takes some time. Don’t worry, it is really very verbose. Finally, you will get something like this:
make[1]: Leaving directory '~/swipl-<version>/src'
Warning: Found 9 issues.
No errors during package build
Now you may run SWI-Prolog interpreter by typing:
<user>@<host>:~/swipl-<version>% cd ~/swipl_intel/lib/swipl-7.4.2/bin/x86_64-linux
<user>@<host>:~/swipl_intel/lib/swipl-<version>/bin/x86_64-linux% ./swipl
Welcome to SWI-Prolog (threaded, 64 bits, version 7.4.2) @ Intel® architecture SWI-Prolog comes with ABSOLUTELY NO WARRANTY.
This is free software. Please run ?- license. for legal details. For online help and background, visit http://www.swi-prolog.org For built-in help, use ?- help(Topic). or ?- apropos(Word). 1 ?-
For exiting the interpreter, type halt. . Now you a ready to use Prolog, powered by Intel® architecture.
You may also save disk space by doing:
<user>@<host>:~/swipl_intel/lib/swipl-<version>/bin/x86_64-linux% cd ~
<user>@<host>:~% rm -r swipl-<version>
Probing Experiment
Until now, there is an Intel compiled version of SWI-Prolog in your computer. Since this experiment intends to compare such combination with another environment, a SWI-Prolog interpreter using a different compiler, such as gcc 5.4.0, is needed. The procedure for building an alternative version is quite similar to the one described in this article.
The Tower of Hanoi puzzle4 is a classical AI problem and it was used for probing the Prolog interpreters. The following code is the most optimized implementation:
move(1,X,Y,_) :-
write('Move top disk from '),
write(X),
write(' to '),
write(Y),
nl.
move(N,X,Y,Z) :-
N>1,
M is N-1,
move(M,X,Z,Y),
move(1,X,Y,_),
move(M,Z,Y,X).
It moves the disks between pylons and logs their moments. When loading such implementation and running a 3 disk instance problem (move(3,left,right,center)), the following output is obtained after 48 inferences:
Move top disk from left to right
Move top disk from left to center
Move top disk from right to center
Move top disk from left to right
Move top disk from center to left
Move top disk from center to right
Move top disk from left to right
true .
This test intends to compare the performance of Intel SWI-Prolog version against gcc compiled version. Note that terminal output printing is a slow operation, so it is not recommended to use it in benchmarking tests since it masquerades results. Therefore, the program was changed in order to provide a better probe with a dummy sum of two integers.
move(1,X,Y,_) :-
S is 1 + 2.
move(N,X,Y,Z) :-
N>1,
M is N-1,
move(M,X,Z,Y),
move(1,X,Y,_),
move(M,Z,Y,X).
Recall that the SWI-Prolog source-code did not seem to be OpenMP ready. However, most loops can be threaded by inserting the macro #pragma omp parallel for right before the loop. Thus, time-consuming loops from SWI-Prolog proof procedure were located and the OpenMP macro was attached to such loops. The source-code was compiled with –openmp option, a third compilation of Prolog interpreter was built, and 8 threads were used. If the reader wishes to build this parallelized version of Prolog, the following must be done.
At ~/swipl-/src/pl-main.c add #include <omp.h> to the header section of pl-main.c; if you chose, you can add omp_set_num_threads(8) inside main method to specify 8 OpenMP threads. Recall that this experiment environment provides 4 cores and hyper threading turned on with 2 threads per core, thus 8 threads are used, otherwise leave it out and OpenMP will automatically allocate the maximum number of threads it can.
int main(int argc, char **argv){
omp_set_num_threads(8);
#if O_CTRLC
main_thread_id = GetCurrentThreadId();
SetConsoleCtrlHandler((PHANDLER_ROUTINE)consoleHandlerRoutine, TRUE);
#endif
#if O_ANSI_COLORS
PL_w32_wrap_ansi_console(); /* decode ANSI color sequences (ESC[…m) */
#endif
if ( !PL_initialise(argc, argv) )
PL_halt(1);
for(;;)
{ int status = PL_toplevel() ? 0 : 1;
PL_halt(status);
}
return 0;
}
At ~/swipl-<version>/src/pl-prof.c add #include <omp.h> to the header section of pl-prof.c; add #pragma omp parallel for right before the for-loop from methods activateProfiler, add_parent_ref, profResumeParent, freeProfileNode, freeProfileData(void).
int activateProfiler(prof_status active ARG_LD){
………. < non relevant source code ommited > …….…
LD->profile.active = active;
#pragma omp parallel for
for(i=0; i<MAX_PROF_TYPES; i++)
{ if ( types[i] && types[i]->activate )
(*types[i]->activate)(active);
}
………. < non relevant source code ommited > ……….
return TRUE;
}
static void add_parent_ref(node_sum *sum,
call_node *self,
void *handle, PL_prof_type_t *type,
int cycle)
{ prof_ref *r;
sum->calls += self->calls;
sum->redos += self->redos;
#pragma omp parallel for
for(r=sum->callers; r; r=r->next)
{ if ( r->handle == handle && r->cycle == cycle )
{ r->calls += self->calls;
r->redos += self->redos;
r->ticks += self->ticks;
r->sibling_ticks += self->sibling_ticks;
return;
}
}
r = allocHeapOrHalt(sizeof(*r));
r->calls = self->calls;
r->redos = self->redos;
r->ticks = self->ticks;
r->sibling_ticks = self->sibling_ticks;
r->handle = handle;
r->type = type;
r->cycle = cycle;
r->next = sum->callers;
sum->callers = r;
}
void profResumeParent(struct call_node *node ARG_LD)
{ call_node *n;
if ( node && node->magic != PROFNODE_MAGIC )
return;
LD->profile.accounting = TRUE;
#pragma omp parallel for
for(n=LD->profile.current; n && n != node; n=n->parent)
{ n->exits++;
}
LD->profile.accounting = FALSE;
LD->profile.current = node;
}
static void freeProfileNode(call_node *node ARG_LD)
{ call_node *n, *next;
assert(node->magic == PROFNODE_MAGIC);
#pragma omp parallel for
for(n=node->siblings; n; n=next)
{ next = n->next;
freeProfileNode(n PASS_LD);
}
node->magic = 0;
freeHeap(node, sizeof(*node));
LD->profile.nodes–;
}
static void freeProfileData(void)
{ GET_LD
call_node *n, *next;
n = LD->profile.roots;
LD->profile.roots = NULL;
LD->profile.current = NULL;
#pragma omp parallel for
for(; n; n=next)
{ next = n->next;
freeProfileNode(n PASS_LD);
}
assert(LD->profile.nodes == 0);
}
The test employs a 20 disk instance problem, which is accomplished after 3,145,724 inferences. The time was measured using Prolog function called time. Each test ran 300 times in a loop and any result that is much higher than others was discarded. Figure 2 presents the CPU time consumed by all three configurations.
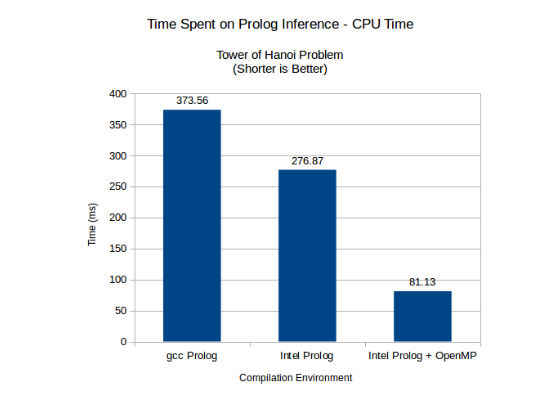
Figure 2: CPU time consumed by SWI-Prolog compiled with gcc, Intel tools, Intel tools+OpenMP.
Considering the gcc compiled Prolog as baseline, the speedup obtained by Intel tools was 1.35. This is a good result since the source-code was not changed at all, parallelism was not explored by the developer and specialized methods were not called, that is, all blind duty was delegated to Intel® C++ Compiler and libraries. When Intel implementation of OpenMP 4.0 was used, the same speedup increased to 4.60x.
Conclusion
This article deliberately paid attention to logic based AI. It shows that benefits with using Intel development tools for AI problems are not restricted to machine learning. A common distribution of Prolog was compiled with Intel® C++ Compiler, Intel® MKL and Intel implementation of OpenMP 4.0. A significant acceleration was obtained, even though the algorithm of Prolog inference mechanism is not easily optimized. Therefore, any solution for a symbolic logic problem, implemented in such Prolog interpreter, will be powered by an enhanced engine.
Source:https://software.intel.com/en-us/articles/building-and-probing-prolog-with-intel-architecture



