
Introduction
This paper introduces Intel software tools recently made available to accelerate deep learning inference in edge devices (such as smart cameras, robotics, autonomous vehicles, etc.) incorporating Intel® Processor Graphics solutions across the spectrum of Intel SOCs. In particular, this paper covers Intel’s Deep Learning Deployment Toolkit (available via the Intel® Computer Vision SDK Beta) and how these tools help developers increase the performance and perhaps even more importantly – the performance per watt of AI Inference in your product. The paper also introduces the underlying Compute Library for Deep Neural Networks(clDNN), a Neural Network kernel optimizations written in OpenCL and available in open source.
Target audience: Software developers, platform architects, data scientists, and academics seeking to maximize deep learning performance on Intel® Processor Graphics.
Note: Artificial Intelligence (AI), Machine Learning (ML), Deep Learning (DL) are used interchangeably in this paper. The larger field is artificial intelligence. This article is focusing on the Machine Learning piece of AI or more specifically the multi-layered neural networks form of Machine Learning called Deep Learning.
Background on AI and the Move to the Edge
Artificial Intelligence or AI has been a domain of research with fits and starts over the last 60 years. AI has increased significantly in the last 5 years with the availability of large data sources, growth in compute engines and modern algorithms development based on neural networks. Machine learning or the many layers of deep learning are propelling AI into all parts of modern life as it is applied to varied usages from computer vision to identification and classification from natural language processing to forecasting. These base level tasks help to optimize decision-making in many areas of life.
As a data scientist Andrew Ng noted. AI is the next electricity: “Just as electricity transformed almost everything 100 years ago, today I actually have a hard time thinking of an industry that I don’t think AI will transform in the next several years.”
This wave of AI work began in the cloud running on servers. While AI usage in the cloud continues to grow quickly, there is a trend to perform AI inference on the edge. This trend to devices performing machine learning locally versus relying solely on the cloud is driven by the need to lower latency, persistent availability, lower costs and address privacy concerns. We are moving to the day that devices from phones and PCs to cars, robots and drones to embedded devices like refrigerators and washing machines all will have AI embedded in them. As Andrew Ng pointed out, companies in all industries are figuring out their AI strategy. Additionally, the field of AI is rapidly changing, with novel topologies being introduced on a weekly basis. This requires product developers to design for flexibility to modify AI software frequently in their products.
Intel® Processor Graphics as a Solution for AI Inference on the Edge
Intel Processor Graphics (Intel® HD Graphics, Intel® Iris™ Graphics and Intel® Iris™ Pro Graphics) provides a good balance of fixed function acceleration with programmability to deliver good performance/power across the emerging AI workloads with the flexibility to allow customers to adopt the latest AI topologies. Specifically, Intel Processor Graphics provides the characteristics of:
Ubiquity – Intel Processor Graphics as part of Intel’s SOCs have already shipped in more than a billion devices ranging from servers to PCs to embedded devices. This makes it a widely available engine to run machine learning algorithms.
Scalability – As AI becomes embedded in every product, the design points of power and performance will vary greatly. Intel Processor Graphics is available in a broad set of power/performance offerings from Intel Atom processors, Intel® Core™ processors, and Intel® Xeon® processors.
Leadership in Media – More than 70% of internet traffic is video. One of the top usages for AI in devices will be computer vision. Along with compute for AI, encoding, decoding and processing video will be employed concurrently. Intel® Quick Sync Video technology is based on the dedicated media capabilities of Intel Processor Graphics to improve the performance and power efficiency of media applications, specifically speeding up functions like decode, encode and video processing. See Intel Quick Sync Video page to learn more. When developers use the Intel® Media SDK or Intel® Media Server Studio – an API provides access these media capabilities and to hardware-accelerated codecs for Windows* and Linux*.
Powerful and Flexible Instruction Set Architecture (ISA) – The Instruction Set Architecture (ISA) of the Processor Graphics SIMD execution units is well suited to Deep Learning. This ISA offers rich data type support for 32bitFP, 16bitFP, 32bitInteger, 16bitInteger with SIMD multiply-accumulate instructions. At theoretical peak, these operations can complete on every clock for every execution unit. Additionally, the ISA offers rich sub register region addressing to enable efficient cross lane sharing for optimized convolution implementations, or efficient horizontal scan-reduce operations. Finally, the ISA provides efficient memory block loads to quickly load data tiles for optimized convolution or optimized generalized matrix multiply implementations.
Memory architecture – When using discrete graphics acceleration for deep learning, input and output data have to be transferred from system memory to discrete graphics memory on every execution – this has a double cost of increased latency and power. Intel Processor Graphics is integrated on-die with the CPU. This integration enables the CPU and Processor Graphics to share system memory, share memory controller, and share portions of the cache hierarchy. Such a shared memory architecture can enable efficient input/output data transfer and even “zero copy” buffer sharing. Additionally, Intel has sku offerings with additional package integrated eDRAM.
Intel’s Deep Learning Deployment Toolkit
To utilize the hardware resources of Intel Processor Graphics easily and effectively, Intel provides the Deep Learning Deployment Toolkit, available via the Intel Computer Vision SDK. This toolkit takes a trained model and tailors it to run optimally for specific endpoint device characteristics. In addition, it delivers a unified API to integrate inference with application logic.
The Deep Learning Deployment Toolkit comprises two main components: the Model Optimizer and the Inference Engine (Figure 1).
Figure 1: Model flow through the Deep Learning Deployment Toolkit
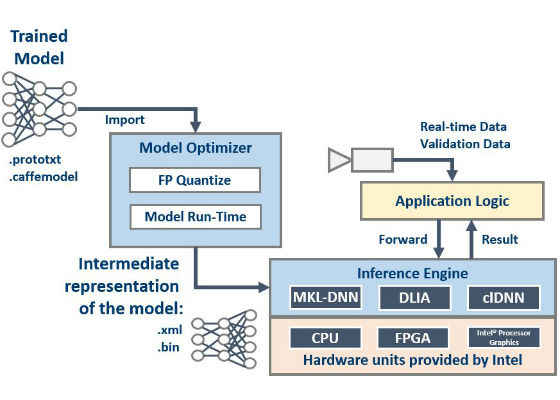
Model Optimizer is a cross-platform command line tool that performs static model analysis and adjusts deep learning models for optimal execution on end-point target devices. In detail, the Model Optimizer:
- Takes as input a trained network in a framework specific format (for example from the Caffe* framework)
- Performs horizontal and vertical fusion of the network layers
- Prunes unused branches in the network
- Quantizes weights
- Produces as output an Internal Representation (IR) of the network – a pair of files that describe the whole model:
- Topology file – an XML file that describes the network topology
- Trained data file – a .bin file that contains the weights and biases binary data
The produced IR is used as an input for the Inference Engine.
Inference Engine is a runtime that delivers a unified API to integrate the inference with application logic.
Specifically it:
- Takes as input an IR produced by the Model Optimizer
- Optimizes inference execution for target hardware
- Delivers inference solution with reduced footprint on embedded inference platforms.
The Deep Learning Deployment Toolkit can optimize inference for running on different hardware units like CPU, GPU and will support FPGA in future. For acceleration on CPU it uses the MKL-DNN plugin – the domain of Intel® Math Kernel Library which includes functions necessary to accelerate the most popular image recognition topologies. It's planned to add FPGA support using plugin for Intel® Deep Learning Inference Accelerator . For GPU, the Deep Learning Deployment Toolkit has clDNN – a library of OpenCL kernels. The next section explains how clDNN helps to improve inference performance.
Compute Library for Deep Neural Networks (clDNN)
clDNN is a library of kernels to accelerate deep learning on Intel® Processor Graphics. Based on OpenCL, these kernels accelerate many of the common function calls in the popular topologies (AlexNet*, VGG*, GoogleNet*, ResNet*, Faster-RCNN*, SqueezeNet* and FCN* are supported today with more being added). To give developers the greatest flexibility and highest achievable performance Intel is delivering:
1) The full library as open source so developers and customers can use existing kernels as models to build upon or create their own hardware specific kernels running deep learning.
2) Compute extensions to expose the full hardware capabilities to developers.
During network compilation clDNN breaks the workflow optimizations into in three stages described below.
Figure 2: Model flow from topology creation to execution
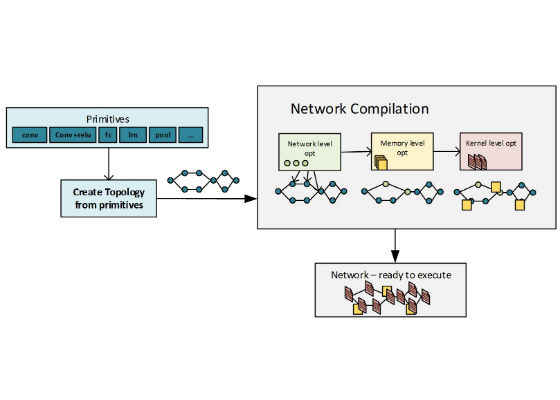
Network Compilation and the 3 Stages of clDNN
Stage 1: Network Level
Fusing is one of most efficient ways to optimize graphs in DL. In clDNN, we have created 2 ways to perform fusing – one more automated to run on a single accelerator (naive inference client) and the second for a more experienced data scientist to tune to run across multiple accelerators (Set of fused primitives). In more detail:
- Naive inference client – you have a workload and want it to be run on one accelerator. In this case user can ask clDNN to perform fusing during network compilation
- Set of fused primitives – in this approach, the user who is experienced in tuning models, does the graph compilation with pattern matching in his application to balance the work across various accelerators. For this approach we expose already fused primitives
Currently clDNN supports 3 fusions: convolution with activation, fully connected with activation and deconvolution with activation fused primitives. Additional fusions are in development.
Another part of network level optimizations is the padding implementation. Choosing OpenCL buffers as data storage requires padding by either adding conditions inside the kernels or providing a buffer with a frame around the input data. The first approach would consume the full register budget, which would constrain the available registers for the convolutions kernels, negatively impacting performance.
Experiments have shown that adding the proper aligned frame around the buffers provides better performance results, when it is done as follows:
Consider network with two primitives A and B. B contains padding equals 2:
Figure 3: Padding Example
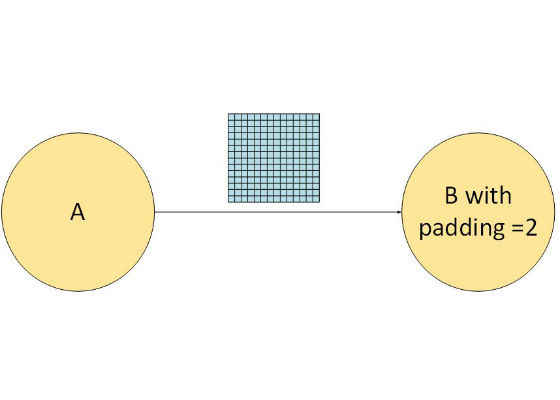
This requires adding a frame with size 2×2:
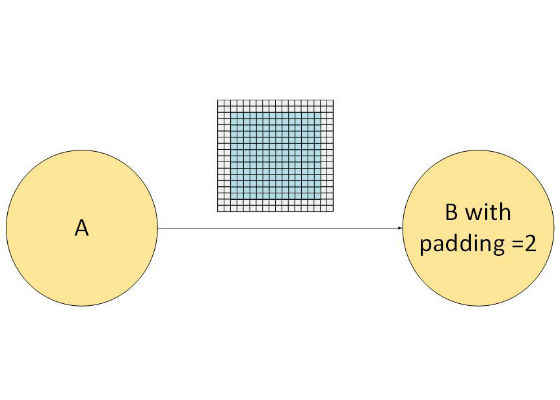
To add the frame we need to add the reorder primitive:
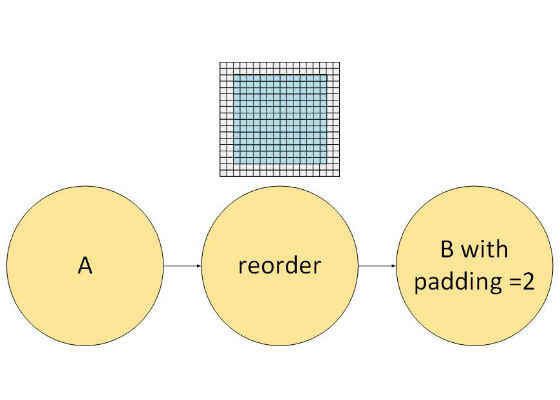
and fuse this with the A primitive:
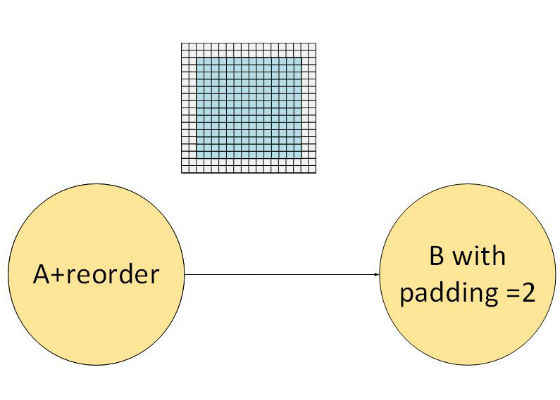
Stage 2: Memory Level
As soon as the topology is defined and data is provided, the network is ready to compile. The first step of network compilation is the determination of the activation layout. In DNN’s, data stored in hidden layers is defined as 4D memory chunks. In clDNN, the layout description is defined with 4 letters:
- B – number of patches in batch
- F – number of feature maps or channels
- X – spatial or width
- Y – spatial or height
Figure 4: Example of a memory chunk
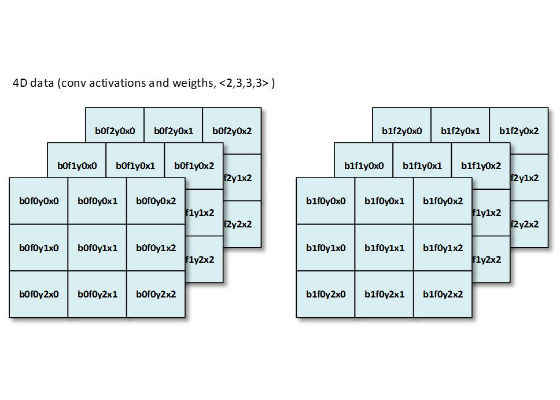
Figure 5: For most cases the most optimal layout is BFYX
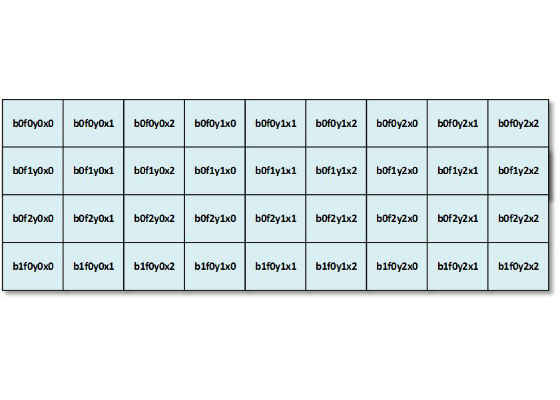
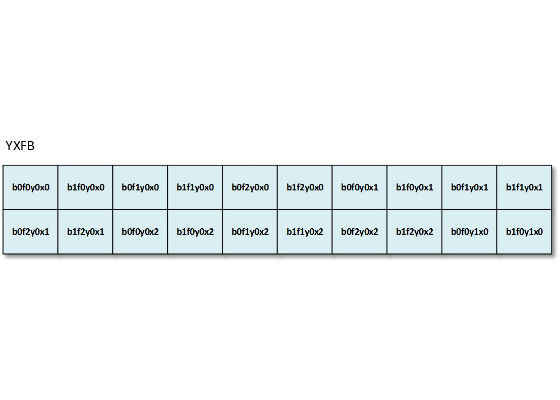
If data type is half precision (fp16), the batch size is greater or equal to 32 and the convolutions are using split parameter (depth split like in Alexnet* convolutions), then the clDNN layout is YXFB.
Figure 6: YXFB layout
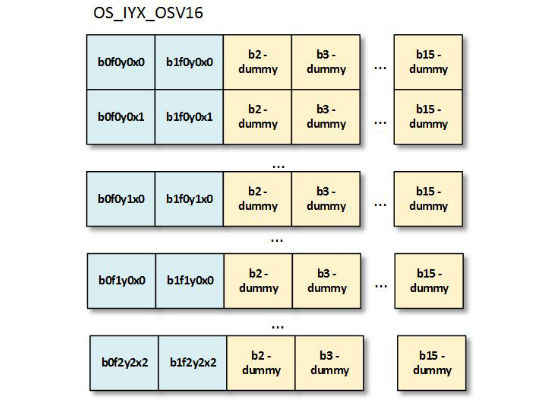
During memory level optimization, after kernels for every primitive have been chosen, clDNN runs weights optimizations, which transform user provided weights into ones that are suitable for the chosen kernel. Weights for convolutions are stored in:
Figure 7: Weights for convolutions in IS_IYX_OSV16
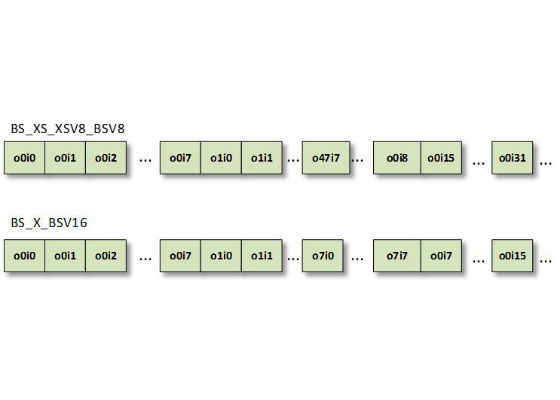
For fully connected networks depending on data type (fp16/fp32), weights can be transformed into one of the following:
Figure 8: memory layouts for optimized fully connected primitives
Stage 3: Kernel Level:
To enable modern topologies in an efficient way on Intel® Processor Graphics, a focus on convolution implementation is needed. To do this, clDNN uses output blocks that enable each thread on the Intel Processor Graphics to compute more than one output at a time. The size of the block depends on the convolution stride size. If the block size is greater than the stride, then clDNN uses shuffle technology to reuse weights and inputs within the neighborhood. This approach yields 85% of performance peak on Alexnet* convolution kernels. All reads and writes are using more optimal block_read/block_write functions. A similar approach is applied to achieve high efficiency running deconvolution and pooling primitives.
Performance Numbers
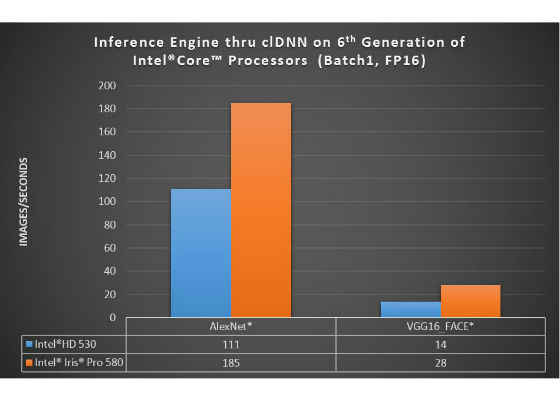
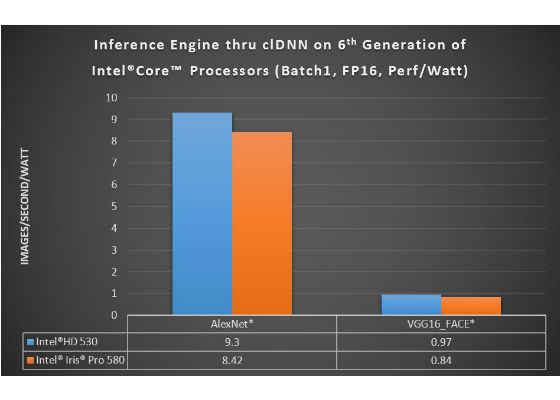
The Intel Iris Pro Graphics provides more peak performance and the Intel HD Graphics provides more performance/watt.
Details:
Batch1 FP16
Intel® HD Graphics 530 (blue) configuration: Intel® Core™ i5-6500 CPU @ 3.20GHz, Intel® HD Graphics 530, fixed frequency – 1000 Mhz, CentOS 7.2 kernel 4.2, OpenCL driver: Intel SRB 4.1., Memory: 2x8GB DDR4 2133
Intel® Iris® Pro Graphics 580 (orange) configuration: Intel® Core™ i7-6770HQ CPU @ 2.60GHz, Intel® Iris® Pro Graphics 580, fixed frequency – 950 Mhz, CentOS 7.2 kernel 4.2, OpenCL driver: Intel SRB 4.1., Memory: 2x4GB DDR4 2133
Topologies: AlexNet*, VGG16-FACE*
Memory Bandwidth vs Compute
In topologies with memory bound sequences (like Alexnet*), we can increase the batch size, reusing weights in multi batches to gain greater images/second performance. But for topologies that are compute bound (like VGG16-FACE*) even with single image on input, we see little benefit with larger batch sizes:
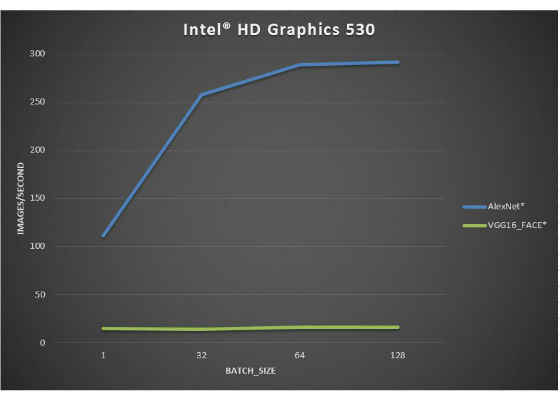
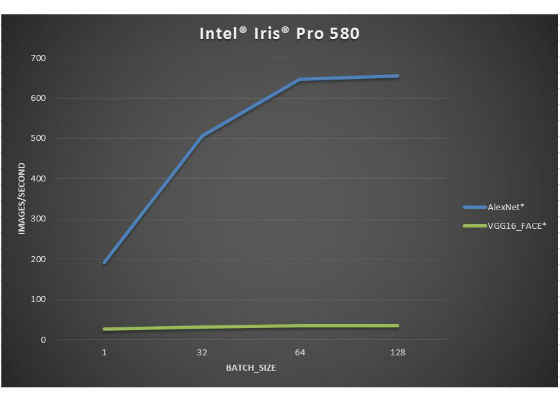
Systems used for these measurements are configured in the same way as at previous pair of benchmarks.
Power Efficiency
In some power constrained workloads, it can be more important to maximize performance/watt versus absolute performance. Since decreasing the clock rate causes the power to decrease linearly but voltage is squared, the GPU performance per Watt is increasing linearly as frequency is lowered. Intel HD Graphics can show a better FPS/Watt ratio running with lower frequency on lower power states. Also different Intel processor products offer different leakage and power behavior. For example the 6th and 7th Generation Intel “Y skus” such as the Intel® Core™ m7-6Y75 Processor with Intel® HD Graphics 515 provide lower peak performance but more performance / watt. Through the combination of selecting the right Intel SOC across a wide range of power and performance points and choosing the appropriate frequency, the developer has the ability to tune to a broad range of workloads and power envelopes.
Conclusion
AI is becoming pervasive, driven by the huge advancements in machine learning and particularly deep learning over the last few years. All devices on the edge are moving toward implementing some form of AI, increasingly performed locally due to cost, latency and privacy concerns. Intel Processor Graphics provides a good solution to accelerate deep learning workloads. This paper described the Deep Learning Model Optimizer, Inference Engine and clDNN library of optimized CNN kernels that is available to help developers deliver AI enabled products to market.
For more such intel IoT resources and tools from Intel, please visit the Intel® Developer Zone
Source:https://software.intel.com/en-us/articles/accelerating-deep-learning-inference-with-intel-processor-graphics



